9. Procesos
|
Tiempo de lectura: 40 minutos |
Los primeros sistemas informáticos solo permitían que un programa se ejecutase cada vez. Dicho programa tenía control completo sobre el sistema y acceso a todos los recursos del mismo. Por el contrario, los sistemas multitarea actuales permiten que múltiples programas sean cargados y ejecutados concurrentemente.
Obviamente esta evolución implica un control más fino y la compartimentación de los diversos programas, para que no interfieran unos con otros. Esto, a su vez, conduce a la aparición de la noción de proceso, que no es sino la unidad de trabajo en un sistema operativo moderno de tiempo compartido.
|
Por simplicidad, en este capítulo utilizaremos los términos trabajo y proceso de forma indistinta. A fin de cuentas tanto los trabajos en los antiguos mainframes como los procesos en los sistemas modernos son la unidad de trabajo en sus respectivos sistemas y el origen de toda actividad en la CPU. |
Por último, antes de continuar, es importante señalar que en un sistema operativo hay varios tipos de procesos:
-
Procesos del sistema. Ejecutan el código del sistema operativo contenido en los programas del sistema, que generalmente sirven para hacer tareas del sistema operativo que es mejor mantener fuera del núcleo.
-
Procesos de usuario. Ejecutan el código contenido en los programas de aplicación.
Sin embargo, en lo que resta de capítulo, no estableceremos ninguna distinción entre ellos. En lo que respecta a la gestión de estos procesos en el sistema, no hay ninguna diferencia.
9.1. El proceso
Como ya hemos comentado con anterioridad, un proceso es un programa en ejecución (véase el Apartado 4.1 para una definición más completa). Sin embargo, los procesos no solo están compuestos por el código del programa, sino que también son importantes otros elementos:
- Segmento de código
-
Contiene las instrucciones ejecutables del programa. También es conocido como segmento text o .text.
- Segmento de datos
-
Contiene las variables globales y estáticas del programa que se inicializan con un valor predefinido. También es conocido como segmento .data.
- Segmento BSS
-
El segmento BSS —siglas de block started by symbol— contiene las variables globales y estáticas del programa inicializadas a 0 o sin inicialización explícita. Como contiene variables globales sin valor inicial, en el ejecutable, generalmente, solo se guarda la longitud que debe tener este segmento en la memoria. También es conocido como segmento .bss.
En el esquema de la Figura 27, este segmento suele ir junto al de datos.
- Pila
-
Contiene datos temporales, como los parámetros y direcciones de retorno de las funciones y las variables locales.
- Montón
-
Contiene el espacio de la memoria que se asigna dinámicamente durante la ejecución del proceso. También es conocido como heap.
- Información sobre el estado actual de ejecución
-
Como el contador de programa, los valores de los registros de la CPU, el estado del proceso y más (véase el Apartado 9.3).
Los segmentos de código, datos y BSS por lo general son secciones dentro del archivo ejecutable que contiene el programa. El resto de elementos los crea el sistema operativo al cargar el programa y crear el proceso.
|
Como vimos en el Apartado 4.1 varios procesos pueden estar asociados al mismo programa, pero no por eso dejan de ser distintos procesos. Todos tendrán una copia del mismo segmento de código, pero diferente: contador de programa, valores en los registros de la CPU, pila, segmento de datos, montón y demas propiedades. |
En la Figura 27 se puede observar la disposición de algunos de estos elementos de un proceso en el espacio de usuario en la memoria.

9.2. Estados de los procesos
Cada proceso tiene un estado que cambia a lo largo de su ejecución y que está definido, parcialmente, por la actividad que realiza actualmente el propio proceso.

Los estados por los que puede pasar un proceso varían de un sistema operativo a otro, aunque los siguientes son comunes a todos ellos:
- Nuevo
-
El proceso está en proceso de creación. Este estado existe porque la creación de un proceso no es algo instantáneo. Necesita de varias operaciones que pueden tardar tiempo en realizarse, como: reservar memoria libre, cargar el programa en la memoria, inicializar estructuras de datos y configurar el entorno de ejecución.
- Ejecutando
-
El proceso está siendo ejecutado en la CPU. Para eso tiene que haber sido escogido por el planificador de la CPU de entre todos los procesos en estado preparado. Solo puede haber un proceso en este estado por CPU en el sistema.
- Esperando
-
El proceso está esperando por algún evento como, por ejemplo, que termine una operación de E/S solicitada previamente o que otro proceso termine su ejecución. Múltiples procesos pueden estar en este estado de espera.
- Preparado
-
El proceso está esperando a poder usar la CPU. Múltiples procesos pueden estar en este estado.
- Terminado
-
El proceso ha finalizado su ejecución y espera a que el sistema operativo recupere los recursos que le fueron asignados. Como en el caso del estado nuevo, este estado existe porque terminar un proceso no es algo instantáneo.
El diagrama de estados de los procesos, con las transiciones posibles entre ellos, se muestra en la Figura 28.
9.3. Bloque de control de proceso
El bloque de control de proceso o PCB (Process Control Block) es una estructura de datos que representa a cada proceso en el sistema operativo y que guarda información sobre su estado de actividad actual.
En el sistema hay un PCB por proceso y sirve de almacén para cualquier información que puede variar de un proceso a otro:
-
Estado del proceso. El estado actual del proceso de la lista que hemos visto anteriormente. Por ejemplo: nuevo, preparado, esperando, etc.
-
Contador de programa. Indica la dirección de la próxima instrucción del proceso que debe ser ejecutada por la CPU. Obviamente, durante el estado ejecutando el contador de programa está en el registro correspondiente de la CPU. Su valor se guarda en el PCB al salir el proceso de la CPU para que comience ejecutarse en ella otro proceso.
-
Registros de la CPU. El valor de los registros de la CPU también forman parte del estado de actividad del proceso. Como en el caso del contador de programa, durante el estado ejecutando los valores están en los registros de la CPU, pero se guardan en el PCB cuando el proceso sale de la CPU para que se ejecute otro proceso.
-
Información de planificación de la CPU. Incluye la información requerida por el planificador de la CPU. Por ejemplo la prioridad del proceso, punteros a las colas de planificación donde está el proceso, punteros al PCB del proceso padre y de los procesos hijos, etc.
-
Información de gestión de la memoria. Incluye la información requerida para la gestión de la memoria. Por ejemplo los valores de los registros base y límite que definen el área de la memoria física que ocupa el proceso —en el caso de se use asignación contigua de memoria (véase el Apartado 15.5 o la dirección a la tabla de páginas —en el caso de que se use paginación (véase el Capítulo 16)—.
-
Información de registro. Aquí se incluye la cantidad de CPU usada, límites de tiempo en el uso de la CPU, estadísticas de la cuenta del usuario a la que pertenece el proceso, estadísticas de la ejecución del proceso, etc.
-
Información de estado de la E/S. Incluye la lista de dispositivos de E/S reservados por el proceso, la lista de archivos abiertos, etc.
9.4. Colas de planificación
En los sistemas operativos hay diferentes colas de planificación para los procesos en distintos estados.
- Cola de trabajo
-
Contiene todos los trabajos en el sistema, de manera que cuando entran en el sistema van a esta cola, a la espera de ser escogidos para ser cargados en la memoria y ejecutados. Esta cola existía en los sistemas multiprogramados, pero no existe en los sistemas operativos modernos.
- Cola de preparados
-
Contiene a los procesos que están en estado preparado. Es decir, procesos cargados en la memoria principal que esperan para usar la CPU. La cola de preparados es generalmente una lista enlazada de PCB, donde cada uno incluye un puntero al PCB del siguiente proceso en la cola.
- Colas de espera
-
Contienen a los procesos que están en estado esperando. Es decir, que esperan por un evento concreto, como por ejemplo la finalización de una petición de E/S. Estas colas también suelen ser implementadas como listas enlazadas de PCB y suele haber una por evento, de manera que cuando ocurre algún evento todos los procesos en la cola asociada pasan automáticamente al estado preparado y a la cola de preparados.
- Colas de dispositivo
-
Son un caso particular de cola de espera. Cada dispositivo de E/S tiene asociada una cola de dispositivo que contiene los procesos que están esperando por ese dispositivo en particular.
Una manera habitual de representar la planificación de procesos es a través de un diagrama de colas como el de la Figura 29.

Analizándolo podemos tener una idea clara del flujo típico de los procesos dentro del sistema:
-
Un nuevo proceso llega al sistema. Una vez pasa del estado nuevo a preparado es colocado en la cola de preparados. Allí espera hasta que es seleccionado por el planificado de la CPU para su ejecución y se le asigna la CPU. Mientras se ejecuta pueden ocurrir varias cosas:
-
El proceso solicita una operación de E/S por lo que abandona la CPU y es colocado en la cola de dispositivo correspondiente en estado esperando. No debemos olvidar que aunque en nuestro diagrama no exista más que una de estas colas, en un sistema operativo real suele haber una para cada dispositivo.
-
El proceso puede querer esperar por un evento. Por ejemplo, puede crear otro proceso y esperar a que termine. En ese caso el proceso hijo es creado, mientras el proceso padre abandona la CPU y es colocado en una cola de espera en estado esperando hasta que el proceso hijo termine. La terminación del proceso hijo es el evento que espera el proceso padre para salir de la cola de espera y entrar en la cola de preparados para continuar su ejecución en la CPU cuando sea posible.
-
El proceso puede ser sacado forzosamente de la CPU, como resultado de la interrupción del temporizador, que permite determinar cuando un proceso lleva demasiado tiempo ejecutándose, así que es colocado en la cola de preparados en estado preparado.
-
-
Cuando las esperas concluyen, los procesos vuelven a la cola de preparado, pasando del estado de espera al de preparado.
-
Los procesos repiten este ciclo hasta que terminan. En ese momento son eliminados de todas las colas mientras el PCB y los recursos asignados son recuperados por parte del sistema operativo para poder usarlos con otros procesos.
9.5. Planificación de procesos
Durante su ejecución, los procesos se mueven entre las diversas colas de planificación a criterio del sistema operativo. Este proceso de selección debe ser realizado por el planificador adecuado:
-
El planificador de largo plazo o planificador de trabajos— selecciona los trabajos desde la cola de trabajos en el almacenamiento secundario —dónde están todos almacenados— y los carga en memoria.
Este planificador se usaba en los sistemas multiprogramados, donde había cola de trabajos. Los sistemas de tiempo compartido posteriores y los sistemas modernos, carecen de planificador de trabajos, porque los programas se cargan directamente en memoria para ser ejecutados, cuando el usuario lo solicita.
-
El planificador de corto plazo o planificador de CPU selecciona uno de los procesos en la cola de preparados y lo asigna a la CPU. Obviamente este planificador es invocado cuando un proceso en ejecución abandona la CPU, dejándola disponible para otro proceso.
-
El planificador de medio plazo era utilizado en algunos sistemas para sacar procesos de la memoria cuando escasea y reintroducirlos posteriormente cuando vuelve a haber suficiente memoria libre. A este esquema se le denomina intercambio —o swapping.
Esto era útil en sistemas antiguos donde un proceso tenía que estar cargado completamente en la memoria para poder ejecutarse. Así que si faltaba memoria, se podía suspender un proceso completo, preservar el contenido de su memoria en disco y liberar la memoria ocupada para usarla con otros procesos.
|
En los sistemas de propósito general modernos no se utiliza planificador de medio plazo porque utilizan técnicas de memoria virtual (véase el Capítulo 17), que permite mover parte de la memoria de los procesos al disco para liberar memoria, sin tener que suspender su ejecución. |
9.6. Cambio de contexto
El cambio de contexto es la tarea de asignar la CPU a un proceso distinto al que la tiene asignada en el momento actual. Esto implica salvar el estado del viejo proceso en su PCB y cargar en la CPU el estado del nuevo. Entre la información que debe ser preservada en el PCB se incluyen:
-
El contador de programa.
-
Los registros de la CPU.
-
El estado del proceso.
-
La información de gestión de la memoria. Por ejemplo, la información necesaria para configurar el espacio de direcciones del proceso.
El cambio de contexto es sobrecarga pura, puesto que no hace ningún trabajo útil mientras se conmuta. Su velocidad depende de aspectos tales como: el número de registros, la velocidad de la memoria y la existencia de instrucciones especiales.
|
Algunas CPU disponen de instrucciones especiales para salvar y cargar todos los registros de manera eficiente. Esto reduce el tiempo que la CPU está ocupada en los cambios de contexto. Otra opción es el uso de juegos de registros, como es el caso de los procesadores Sun UltraSPARC e Intel Itanium. Con ellos el juego de registros actual de la CPU se mapea sobre un banco de registros mucho más extenso. Al hacer cambio de contexto, se mapea el juego de registros a otros registros diferentes del banco. Esto permite a la CPU almacenar de forma eficiente el valor de los registros de más de un proceso, sin que en cada cambio de contexto sea necesario copiarlos al PCB del proceso en la memoria principal. |
9.7. Operaciones sobre los procesos
En general es necesario que los procesos pueden ser creados y eliminados dinámicamente, por lo que los sistemas operativos deben proporcionar servicios para la creación y terminación de los mismos.
9.7.1. Creación de procesos
Un proceso —denominado padre— puede crear múltiples procesos —los hijos— utilizando una llamada al sistema específica para la creación de procesos. Cada proceso creado se identifica de manera unívoca mediante un identificador de proceso o PID (Process Identifier), que normalmente es un número entero.
Por ejemplo en sistemas POSIX un programa puede crear otro proceso así:
pid_t pid = fork();mientras que en Windows API es así:
PROCESS_INFORMATION pi = {0};
if ( CreateProcess( "C:\\Windows\\System32\\charmap.exe", /* ... */, &pi )) (1)
{
DWORD pid = pi.dwhProcessId; (2)
HANDLE handle = pi.hProcess; (3)
}| 1 | CreateProcess() devuelve TRUE si el proceso se creó con éxito. |
| 2 | PROCESS_INFORMATION contiene el identificador de proceso del nuevo proceso, si CreateProcess() ha tenido éxito. |
| 3 | PROCESS_INFORMATION también contiene el manejador del proceso —o handle en inglés— que sirve para obtener y manipular el nuevo proceso. |
En ambos casos pid identifica al nuevo proceso en el sistema.
Sin embargo, mientras que los sistemas POSIX ese identificador se puede usar en otras llamadas al sistema para indicar futuras operaciones sobre el proceso, en Windows lo que se utiliza es el manejador hProcess devuelto en PROCESS_INFORMATION.
Obviamente, cada proceso puede obtener del sistema su propio identificador de procesos:
/* POSIX API */
pid_t pid = getpid();
/* Windows API */
HANDE handle = GetCurrentProcess();
DWORD pid = GetProcessId( handle );o el de su padre:
/* POSIX API */
pid_t parent = getppid();Árbol de procesos
Puesto que cada nuevo proceso puede a su vez crear otros procesos, al final se acaba obteniendo un árbol de procesos. En los sistemas POSIX es muy sencillo de ver ejecutando el comando pstree.
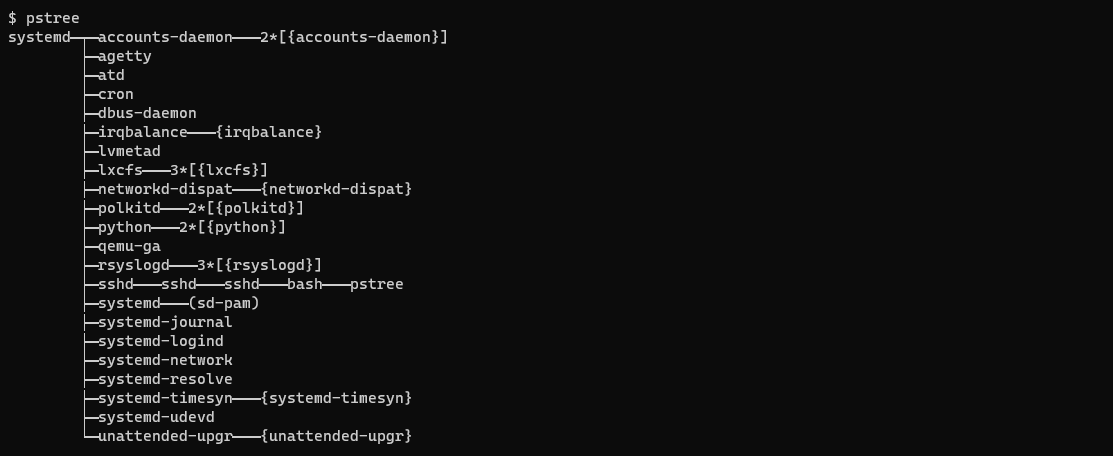
En estos sistemas se conoce como proceso init al proceso padre raíz de todos los procesos de usuario. Su PID siempre es 1, ya que es el primer proceso creado por el sistema operativo al terminar la inicialización del núcleo. Por lo tanto, es el responsable de crear todos los otros procesos que son necesarios para el funcionamiento del sistema.
En la Figura 30 se observa que systemd es el proceso init, como ocurre frecuentemente en muchos sistemas Linux actuales.
Anteriormente, lo común es que los sistemas Linux emplearan una implementación de init basada en la de los UNIX System V.
Cómo obtienen los procesos hilos los recursos que necesitan
Hay varios aspectos en la creación de los procesos que pueden variar de un sistema operativo a otro. Uno de ellos es cómo obtienen los procesos hilos los recursos que necesitan para hacer su trabajo.
Fundamentalmente existen dos alternativas:
-
Que cada proceso hijo pueda solicitar y obtener los recursos directamente del sistema operativo, compitiendo por los recursos del sistema en las mismas condiciones que el resto de procesos en ejecución. Esta es la opción más común en los sistemas de propósito general actuales, como Microsoft Windows, Android, Linux, macOS, UNIX BSD y muchos otros.
-
Que los procesos hijo solo puedan aspirar a obtener un subconjunto de los recursos de su padre. Esto es interesante en sistemas diseñados para ser muy robustos, ya que evita que un proceso pueda sobrecargar el sistema creando múltiples procesos que consuman demasiada memoria o tiempo de CPU.
En este último caso, el proceso padre puede estar obligado a repartir sus recursos entre los procesos hijo. O puede que el sistema les permita compartir algunos de esos recursos —como memoria o archivos— con algunos de sus hijos.
Cómo pasar parámetros de inicialización a los procesos hijo
Generalmente, el proceso padre suele disponer de algún mecanismo para pasar parámetros de inicialización a sus procesos hijo.
Argumentos de línea de comandos
Por ejemplo, en Windows API un proceso puede usar el segundo argumento de CreateProcess() para indicar al proceso hijo opciones y argumentos de línea de comandos:
HANDLE handle = CreateProcess("C:\\holamundo.exe", "/v /s foo.txt bar.png", /* ... */ );Si el proceso hijo está programado en C o C++, podrá acceder a los argumentos /v, /s, foo.txt y bar.png a través de los argumentos argc y argv de la función main() del programa:
int main (int argc, char* argv[])
{
/* . . . */
}de forma que argv[0] contendrá /v, argv[2] contendrá /s y así sucesivamente.
Obviamente, en otros lenguajes de programación se accede de manera diferente a estos argumentos de línea de comandos.
Variables de entorno
Otra forma de pasar parámetros a un proceso hijo es usando las variables de entorno, que no son sino variables dinámicas que se pueden crear, leer y modificar durante la ejecución del proceso.
Las variables de entorno se gestionan con funciones específicas ofrecidas por la API del sistema operativo:
| POSIX API | Windows API | |
|---|---|---|
Leer |
||
Leer todos |
||
Crear / modificar |
por ejemplo, en sistemas POSIX un programa puede leer la variable de entorno PATH así:
char* path = getenv("PATH");mientras que en Windows API es así:
DWORD buffSize = 4096;
TCHAR path[buffSize];
GetEnvironmentVariable("PATH", path, buffSize); (1)| 1 | El valor de la variable de entorno PATH se copia en path. |
Usando setenv() o SetEnvironmentVariable() de forma similar, cualquier proceso puede crear variables de entorno que serán accesibles a sus procesos hijos, porque por defecto los nuevos procesos heredan un duplicado de las variables de entorno de su proceso padre. Así se pueden pasar parámetros de configuración para alterar el comportamiento de los procesos hijo.
Todas las variantes de sistemas UNIX, así como MS-DOS y todas las versiones de Microsoft Windows soportan variables de entorno.
Herencia de recursos
En algunos sistemas operativos los procesos hijos pueden heredar cierto tipo de recursos del proceso padre, lo que también puede servir para inicializar y alterar el comportamiento del proceso hijo.
Por ejemplo, en los sistemas POSIX todos los archivos abiertos por un proceso son heredados en el mismo estado por sus hijos. Lo interesante es que en estos sistemas muchos recursos se gestionan como archivos. Algunos ejemplos podrían ser: dispositivos de E/S, memoria compartida, tuberías, sockets y otros mecanismos de comunicación.
En POSIX todo proceso tiene, por defecto, tres archivos abiertos que corresponden a tres dispositivos de E/S especiales:
-
Entrada estándar, de donde los procesos leen la entrada del teclado de la terminal.
-
Salida estándar, donde el proceso escribe para mostrar texto en la pantalla de la terminal.
-
Salida de error, usada para mostrar errores en la pantalla de la terminal.
Debido a la herencia de los archivos abiertos del proceso padre, todo proceso hijo tiene acceso a estos tres mismos dispositivos. Y a su vez también la tendrán sus hijos y los hijos de estos. De esta manera, todo proceso tiene acceso a los dispositivos de E/S de la terminal donde se ejecuta. Pero también permite a un proceso controlar el destino de la E/S de un proceso hijo —y de los hijos de este—.
Por ejemplo, si antes de crear el proceso hijo sustituye el dispositivo de salida estándar por un archivo real, todo lo que el hijo intente mostrar por pantalla se guardará en dicho archivo, en lugar de mostrarse. Mientras que si lo hace con el dispositivo de entrada estándar, todo lo que pretenda leer de teclado realmente lo leerá de un archivo que el padre puede haber preparado, como si de algún tipo de control remoto se tratara.
|
Esta misma idea se puede extender a procesos que ofrecen servicios, ya sea a otros procesos del mismo sistema o a redes de ordenadores, como Internet. Cada conexión con un cliente es como archivo abierto, por lo que los hijos del proceso heredan las conexiones. Así que es común la estrategia de crear un hijo por conexión para que la atienda en nombre del padre, mientras este se encarga de recibir nuevas conexiones. |
En Microsoft Windows existe un mecanismo similar pero no por defecto. La función CreateProcess() de Windows API permite indicar si se quiere que el nuevo proceso herede los recursos abiertos. Y también tiene ajustes específicos para la entrada y salida estándar y la salida de error del nuevo proceso.
Qué ocurre con la ejecución del padre
Se suelen contemplar dos posibilidades en términos de la ejecución del padre:
-
Que el padre continúe ejecutándose al mismo tiempo que el hijo. Es lo más común en los sistemas multitarea actuales.
-
Que el padre quede detenido a la espera de que algunos o todos sus hijos terminen. Era lo más frecuente en sistemas monotarea, como MS-DOS.
Cómo se construye el espacio de direcciones de los procesos hijo
En general hay dos posibilidades:
-
Que el espacio de direcciones del proceso hijo sea un duplicado del que tiene el padre. Es decir, que inicialmente el hijo tenga el mismo código y datos que el padre. Es lo que hace fork() en los sistemas POSIX.
-
Que el espacio de direcciones del proceso hijo se cree desde cero y se cargue en él un nuevo programa. Es lo que hace CreateProcess() en Windows. Por eso siempre hay que indicarle el nombre del programa que se quiere ejecutar en el nuevo proceso.
Esto lo veremos con más detalle en el Apartado 9.7.3.
9.7.2. Terminación de procesos
Un proceso termina cuando se lo indica al sistema operativo con la llamada al sistema exit. En ese momento puede devolver un valor de estado a su padre.
El proceso padre puede esperar a que el hijo termine y recuperar ese valor a través de la llamada al sistema wait. Cuando un proceso termina, todos los recursos son liberados, incluyendo: la memoria física y virtual, archivos y dispositivos abiertos, búferes de E/S, etc.
| POSIX API | Windows API | |
|---|---|---|
Salir |
||
Esperar (un hijo concreto) |
||
Esperar (múltiples hijos) |
||
Terminar otro proceso |
En todo caso un proceso puede provocar la terminación de otro proceso a través de una llamada al sistema. Por ejemplo, en sistemas POSIX se usa un mecanismo llamado señales:
kill(pid, SIGTERM);mientras que en Windows API:
TerminateProcess(handle);Habitualmente el proceso que invoca estas funciones es el proceso padre, ya que puede que sea el único con permisos para hacerlo.
Los motivos para terminar un proceso hijo pueden ser:
-
El hijo ha excedido el uso de algunos de los recursos reservados. Obviamente esto tiene sentido cuando los hijos utilizan un subconjunto de los recursos asignados al padre.
-
La tarea asignada al hijo ya no es necesaria. Por ejemplo, se creó para comprimir un archivo, pero el usuario ha pedido cancelar la operación.
-
El padre termina y el sistema operativo está diseñado para no permitir que el hijo pueda seguir ejecutándose si no tiene un padre. En esos sistemas, la terminación de un proceso provoca que el sistema operativo inicie lo que se denomina una terminación en cascada, en la que termina todos los procesos que cuelgan de dicho proceso.
|
En sistemas UNIX y estilo UNIX, si un proceso muere a sus hijos no terminan sino que se les reasigna como padre el proceso init. |
9.7.3. Ejemplos de operaciones con procesos
En C estándar la función system() de la librería estándar permite ejecutar otro proceso, con sus argumentos, esperar a que termine y obtener el valor de estado con el que finalizó el proceso.
int status = system("holamundo -v foo.txt");Esta función es portable. Está disponible en cualquier sistema donde haya un compilador de C estándar, pero sus funcionalidades son bastante limitadas. Por ejemplo, no permite que el programa padre continúe su ejecución mientras se ejecuta el hijo, aunque el sistema sea multitarea y ese sea el comportamiento por defecto. Tampoco facilita el control de los recursos que son heredados por el proceso hijo o hacer redirecciones de los dispositivos de E/S estándar.
Como hemos comentado anteriormente, para acceder a todas las funcionalidades ofrecidas por los sistemas operativos, muchas veces es necesario utilizar directamente la librería del sistema.
Windows API
En Windows la librería del sistema ofrece la función CreateProcess(). A diferencia de system(), recibe muchísimos argumentos, ya que permite configurar bastantes aspectos de la creación de un nuevo proceso.
En el Ejemplo 2 se puede ver cómo se usa CreateProcess() para ejecutar un programa y esperar a que termine, de forma similar a como lo hace system().
El código fuente completo de este ejemplo está disponible en createprocess.c.
STARTUPINFO si = { sizeof(STARTUPINFO) }; (1)
PROCESS_INFORMATION pi = {0}; (2)
// Crear procesos hijo y comprobar si no se creó con éxito.
if( ! CreateProcess( (3)
NULL, (4)
"C:\\Windows\\System32\\charmap.exe", (4) (5)
NULL,
NULL,
FALSE, (6)
0,
NULL, (7)
NULL, (8)
&si,
&pi ))
{
fprintf( stderr, "Error (%d) al crear el proceso.\n", GetLastError() ); (9)
return EXIT_FAILURE;
}
printf( "[PADRE] El PID del nuevo proceso hijo es: %d\n", pi.dwProcessId );
// Esperar hasta que el hijo termine.
WaitForSingleObject( pi.hProcess, INFINITE ); (10)
DWORD dwExitCode;
GetExitCodeProcess( pi.hProcess, &dwExitCode ); (11)
printf( "[PADRE] El valor de salida del proceso hijo es: %d\n", dwExitCode );
// Cerrar los manejadores del proceso y del hilo principal del proceso.
CloseHandle( pi.hProcess ); (12)
CloseHandle( pi.hThread );| 1 | STARTUPINFO sirve para pasar a CreateProcess() parámetros adicionales sobre el inicio de la aplicación, como configurar la redirección de la E/S estándar o características de la primera ventana creada por la aplicación —en aplicaciones con interfaz gráfica—. Si no se va a usar, debe inicializarse a 0, excepto el primer campo que debe contener el tamaño de la estructura. |
| 2 | PROCESS_INFORMATION sirve para devolver el manejador y el identificador de proceso del nuevo proceso. Es común inicializar la estructura a 0. |
| 3 | CreateProcess() devuelve TRUE o FALSE, en función de si ha tenido éxito o no, respectivamente. |
| 4 | El primer argumento —lpApplicationName— se usa para pasar la ruta del ejecutable, mientras que los argumentos de línea de comando generalmente se pasan por el segundo —lpCommandLine—.
Si en lpApplicationName se indica NULL, se puede pasar todo junto por lpCommandLine. |
| 5 | En lpCommandLine indicamos la ruta al ejecutable y los argumentos de la línea de comandos, si hicieran falta. |
| 6 | Con bInheritHandles a FALSE señalamos que no queremos que el proceso hijo herede ningún manejador abierto del proceso padre.
Estos manejadores son recursos a los que el padre tiene acceso y, si fuera necesario, el hijo también podría tenerlo.
Los manejadores pueden representar, por ejemplo, archivos abiertos, tuberías, sockets u otros mecanismos de comunicación, procesos o archivos mapeados en memoria, entre muchos otros tipos de recursos. |
| 7 | Con NULL en lpEnvironment indicamos que el hijo herede el conjunto de variables de entorno directamente del padre.
La otra opción es indicar un nuevo conjunto de variables de entorno. |
| 8 | lpCurrentDirectory sirve para indicar el directorio del trabajo del proceso hijo.
Es decir, el directorio respecto al que se resolverán las rutas de archivo relativas.
Con NULL indicamos que utilice la misma ruta que el proceso padre. |
| 9 | Si CreateProcess() falla, devuelve FALSE.
Llamando a GetLastError() obtiene el código que identifica el motivo del error de la última función utilizada de Windows API. |
| 10 | Usando WaitForSingleObject() hacemos que el proceso padre se quede en estado esperando —sin que pueda seguir ejecutándose— hasta que el proceso hijo termine. |
| 11 | Cuando el proceso ha terminado, el padre puede conocer su valor de salida.
Es decir, el valor usado para terminar en la sentencia return de main() o al llamar a ExitProcess() en el programa del proceso hijo.
Como convención, el hijo indica con un 0 que terminó con éxito, mientras que con un valor distinto indica que tuvo algún tipo de problema. |
| 12 | Cuando ya no hace falta obtener información del proceso hijo o manipularlo, es necesario cerrar los manejadores devueltos por CreateProcess(). Así el sistema operativo sabe que las estructuras de datos relacionadas con el proceso hijo ya no son necesarias, por lo que pueden liberarse. |
CreateProcess() siempre necesita la ruta a un ejecutable —sea en el primer o en el segundo argumento de la función— porque se utiliza para crear un proceso completamente limpio y ejecutar en él un nuevo programa.
POSIX API
Por el contrario, en los sistemas POSIX se utiliza una estrategia muy diferente. Los nuevos procesos se crean con la llamada fork(), que se encarga de crearlo como una copia del proceso padre.
El código fuente completo de este ejemplo está disponible en fork.c.
pid_t pid = getpid(); (7)
// Crear un proceso hijo
pid_t child = fork(); (1)
if (child == 0) (2)
{
// Aquí solo entra el proceso hijo
puts( "[HIJO] ¡Soy el proceso hijo!" );
printf( "[HIJO] El valor de mi variable 'child' es: %d\n", child ); (2)
printf( "[HIJO] Este es mi PID: %d\n", getpid() ); (4)
printf( "[HIJO] El valor de mi variable 'pid' es: %d\n", pid ); (7)
printf( "[HIJO] El PID de mi padre es: %d\n", getppid() ); (7)
puts( "[HIJO] Durmiendo 10 segundos..." );
sleep(10);
int status = 42;
printf( "[HIJO] Salgo con %d ¡Adios!\n", status );
return status; (9)
}
else if (child > 0) (3) (4)
{
// Aquí solo entra el proceso padre
puts( "[PADRE] ¡Soy el proceso padre!" );
printf( "[PADRE] El valor de mi variable 'child' es: %d\n", child ); (3) (4)
printf( "[PADRE] Este es mi PID: %d\n", getpid() ); (7)
printf( "[PADRE] El valor de mi variable 'pid' es: %d\n", pid ); (7)
printf( "[PADRE] El PID de mi padre es: %d\n", getppid() );
puts( "[PADRE] Voy a esperar a que mi hijo termine..." );
int status;
wait( &status ); (8) (9)
printf( "[PADRE] El valor de salida de mi hijo fue: %d\n", WEXITSTATUS(status) ); (9)
puts( "[PADRE] ¡Adios!" );
return EXIT_SUCCESS;
}
else { (5)
// Aquí solo entra el padre si no pudo crear el hijo
fprintf( stderr, "Error (%d) al crear el proceso: %s\n", errno, strerror(errno) ); (6)
return EXIT_FAILURE;
}| 1 | El proceso llama a fork() pero al retornar de la llamada vuelven dos procesos: el proceso padre, que es el que llamó originalmente a fork(), y el proceso hijo.
Como el proceso hijo es una copia del padre, tiene el mismo código, las mismas variables y los mismos recursos que tenía el padre en el momento de llamar a fork().
La única diferencia es el valor devuelto por fork(), que guardamos en child. |
| 2 | Los dos procesos ejecutan el mismo programa, así que ambos llegan a la línea detrás del fork().
Como queremos que cada proceso haga cosas diferentes, necesitamos que cada uno vaya a ramas distintas del código.
Eso se hace comprobando el valor de child, porque si vale 0 es que el proceso que actualmente ejecuta el programa es el hijo. |
| 3 | Si, por el contrario, el valor de child es mayor de 0, el proceso que ejecuta el programa es el padre y el valor de child es el PID del proceso hijo creado. |
| 4 | Así que el valor de child en el padre coincide con el devuelto por getpid() en el hijo. |
| 5 | Finalmente, si el valor devuelto por fork() es negativo, es que ocurrió un error y el proceso hijo no llegó a crearse. |
| 6 | En los sistemas POSIX es común que las llamadas al sistema devuelvan un valor negativo para indicar un error. El motivo del error se puede conocer a través de la variable global errno, que siempre guarda el código de identificación del error en la última función invocada de la API POSIX. La función strerror() permite obtener un texto descriptivo de cualquier valor de errno, lo que siempre resulta útil para crear mensajes de error que ayuden a determinar dónde estuvo el problema. |
| 7 | A modo de ejemplo hemos guardado el PID del proceso en la variable pid, antes de la llamada a fork().
Como el proceso hijo es una copia del proceso padre, la variable existe en ambos, pero en el proceso hijo su valor coincide con lo devuelto por getppid() mientras que en el proceso padre con lo devuelto por getpid(). |
| 8 | wait() hace que el proceso padre interrumpa su ejecución hasta que algún hijo termine y devuelve el estado de salida en status.
|
| 9 | El valor de salida del proceso hijo lo obtiene el proceso padre a través del estado de salida devuelto por wait().
Pero ese estado contiene más información sobre la causa por la que el proceso terminó.
Para recuperar el valor de salida se usa la macro WEXITSTATUS sobre el estado de salida. |
Lo siguiente es un posible resultado de ejecutar el programa anterior en una terminal de Linux, numerado con las anotaciones realizadas al código:
$ ./fork [PADRE] ¡Soy el proceso padre! [PADRE] El valor de mi variable 'child' es: 2360 (4) [PADRE] Este es mi PID: 2359 (7) [PADRE] El valor de mi variable 'pid' es: 2359 (7) [HIJO] ¡Soy el proceso hijo! [PADRE] El PID de mi padre es: 1857 [PADRE] Voy a esperar a que mi hijo termine... [HIJO] El valor de mi variable 'child' es: 0 (2) [HIJO] Este es mi PID: 2360 [HIJO] El valor de mi variable 'pid' es: 2359 (7) [HIJO] El PID de mi padre es: 2359 (7) [HIJO] Durmiendo 10 segundos... [HIJO] Salgo con 42 ¡Adios! (9) [PADRE] El valor de salida de mi hijo fue: 42 (9) [PADRE] ¡Adios!
Aunque pueda parecer algo complejo, esta estrategia facilita la comunicación entre procesos. Es muy sencillo lanzar otro proceso para hacer una tarea en paralelo que tendrá automáticamente una copia de los datos del proceso original.
Como se trata de una copia, las nuevas variables o la modificación de variables existentes que realice cualquiera de los procesos, no serán visibles para el otro. Es decir, después del fork() ambos procesos son completamente independientes. Pero como el proceso hijo hereda el acceso a todo tipo de recursos abiertos por el proceso padre, como: archivos, tuberías, sockets o regiones de memoria compartida, entre muchos otros recursos; es muy sencillo crear un canal de comunicación entre ambos procesos, si fuera necesario.
Sin embargo, fork() no proporciona una funcionalidad similar a la de system(). No sirve para crear otro proceso con un programa diferente. Para eso necesitamos exec(), una familia de funciones cuyo propósito es cargar un nuevo programa en el proceso que la invoca.
El código fuente completo de este ejemplo está disponible en fork-exec.c.
// Crear un proceso hijo
pid_t child = fork(); (1)
if (child == 0)
{
// Aquí solo entra el proceso hijo
puts( "[HIJO] ¡Soy el proceso hijo!" );
puts( "[HIJO] Voy a ejecutar el comando 'ls'" );
/* Hacer otras cosas necesarias antes de ejecutar el programa... */ (4)
execl( "/bin/ls", "ls", "-l", NULL ); (2) (3) (5)
fprintf( stderr, "Error (%d) al ejecutar el programa: %s\n", errno, strerror(errno) ); (6)
return EXIT_FAILURE; (7)
}
else if (child > 0)
{
// Aquí solo entra el proceso padre
puts( "[PADRE] ¡Soy el proceso padre!" );
puts( "[PADRE] Voy a esperar a que mi hijo termine..." );
int status;
wait( &status ); (8)
printf( "[PADRE] El valor de salida de mi hijo fue: %d\n", WEXITSTATUS(status) );
puts( "[PADRE] ¡Adios!" );
return EXIT_SUCCESS;
}
else {
// Aquí solo entra el padre si no pudo crear el hijo
fprintf( stderr, "Error (%d) al crear el proceso: %s\n", errno, strerror(errno) );
return EXIT_FAILURE;
}| 1 | Primero creamos un proceso hijo, donde ejecutaremos el nuevo programa. Si nos diera por llamar directamente a una función de la familia exec(), nuestro programa sería sustituido y no tendríamos ningún control sobre lo que pase después. |
| 2 | En la rama de código que se va a ejecutar en el hijo —gracias a la comprobación del valor devuelto por fork()— ejecutamos la función de la familia exec() que más nos interese. Esta función no crea otro proceso, sino que carga el programa indicado en el proceso hijo, sustituyendo así a nuestro programa. |
| 3 | Todas las funciones de la familia exec() reciben como primer argumento la ruta al ejecutable, pero en execlp() en particular, a continuación se indican los argumentos de línea de comandos, tal y como queremos que los reciba el programa en el argumento argv de su main().
Es decir, que el programa del comando /bin/ls recibirá ls y -l en argv[0] y argv[1], respectivamente.
El NULL del final indica cuando no hay más argumentos de línea de comandos para pasar. |
| 4 | Antes de ejecutar la función exec() se pueden hacer cosas para configurar adecuadamente el proceso donde se ejecutará el nuevo programa. Por ejemplo, cambiar las variables de entorno, redirigir la E/S estándar, cambiar el usuario al que pertenece el proceso —si originalmente se ejecuta con un usuario con ese privilegio— o cerrar archivos abiertos del proceso padre que ha heredado el proceso hijo y que, obviamente, no queremos que se queden abiertos para programas diferentes al nuestro. |
| 5 | Las funciones exec() no retornan si tienen éxito, porque el programa actual es sustituido por el indicado, que comenzará a ejecutarse de su main(). |
| 6 | Si la función exec() retorna es porque falló y, como es común, el motivo del error está disponible en errno. Un motivo de fallo muy típico es que el ejecutable indicado no exista. |
| 7 | Si la función exec() retorna, la ejecución del programa en el proceso hijo continúa hasta salir de main(). Generalmente, el proceso hijo no es útil si no puede ejecutar el programa que le hemos indicado. Por eso es importante asegurarnos de que el proceso hijo termina, si exec() falla. |
| 8 | Mientras todo lo anterior ocurre en el proceso hijo, el proceso padre espera. Cuando el proceso hijo termine, el padre podrá obtener su estado de salir para saber si tuvo éxito o no. |
Lo siguiente es un posible resultado de ejecutar el programa anterior en una terminal de Linux, numerado con las anotaciones realizadas al código:
$ ./fork-exec [PADRE] ¡Soy el proceso padre! [PADRE] Voy a esperar a que mi hijo termine... [HIJO] ¡Soy el proceso hijo! [HIJO] Voy a ejecutar el comando 'ls' total 628 (2) -rwxr--r-- 1 jesus jesus 72640 Sep 16 13:41 fifo-client -rwxr--r-- 1 jesus jesus 72784 Sep 16 13:41 fifo-server -rwxr--r-- 1 jesus jesus 20056 Sep 16 13:41 fork -rwxr-xr-x 1 jesus jesus 19896 Sep 18 13:24 fork-exec -rwxr--r-- 1 jesus jesus 80744 Sep 16 13:41 mmap -rwxr--r-- 1 jesus jesus 45712 Sep 16 13:41 pipe -rwxr--r-- 1 jesus jesus 87024 Sep 16 13:41 shared-memory -rwxr--r-- 1 jesus jesus 77696 Sep 16 13:41 shared-memory-sync -rwxr--r-- 1 jesus jesus 19608 Sep 16 13:41 softstack-c -rwxr--r-- 1 jesus jesus 39328 Sep 16 13:41 softstack-cpp -rwxr--r-- 1 jesus jesus 9920 Sep 16 13:41 syscall -rwxr--r-- 1 jesus jesus 40712 Sep 16 13:41 threads-mutex-pthread -rwxr--r-- 1 jesus jesus 39944 Sep 16 13:41 threads-pthread [PADRE] El valor de salida de mi hijo fue: 0 (8) [PADRE] ¡Adios!
Veamos qué ocurre si la línea de la función exec() fuera:
execl( "/bin/ls", "ls", "-l", "/foo", NULL );para intentar ver el contenido del directorio /foo, que no existe:
$ ./fork-exec [PADRE] ¡Soy el proceso padre! [PADRE] Voy a esperar a que mi hijo termine... [HIJO] ¡Soy el proceso hijo! [HIJO] Voy a ejecutar el comando 'ls' ls: cannot access '/foo': No such file or directory (1) [PADRE] El valor de salida de mi hijo fue: 2 (2) [PADRE] ¡Adios!
| 1 | El comando ls se ejecuta, pero falla porque el directorio indicado no existe. |
| 2 | Por eso el programa, al terminar el proceso, no devuelve 0 si no 2 y es ese el valor que recibe el proceso padre.
Esto le permite saber al proceso padre que el comando ls no tuvo éxito. |
Y finalmente cambiemos la línea de la función exec() así:
execl( "/noexists", "ls", "-l", NULL );para que intente ejecutar un programa que no existe:
$ ./fork-exec [PADRE] ¡Soy el proceso padre! [PADRE] Voy a esperar a que mi hijo termine... [HIJO] ¡Soy el proceso hijo! [HIJO] Voy a ejecutar el comando 'ls' Error (2) al ejecutar el programa: No such file or directory (1) [PADRE] El valor de salida de mi hijo fue: 255 (2) [PADRE] ¡Adios!
| 1 | exec() falla y se muestra el mensaje de error con el motivo. |
| 2 | El proceso hijo termina con -1 y así llega ese valor al proceso padre. Al utilizar un valor de salida diferente a los que usa el programa que intenta ejecutar, el padre distingue las terminaciones causadas por errores al llamar a exec() de los errores del propio programa. |
Todas las funciones exec() hacen lo mismo. Primero liberan la memoria reservada en el proceso, después cargan el nuevo programa y finalmente inicia la ejecución del programa desde su punto de entrada. La diferencia entre las distintas funciones está en los argumentos que aceptan. Esa diferencia se puede conocer fijándonos en las letras al final del nombre de cada función:
-
Sin 'p', como
execl()oexecv(), el primer argumento de la función es la ruta hasta el ejecutable del programa que se quiere ejecutar. -
Con 'p', como
execlp()oexecvp(), la función busca el ejecutable como lo hace la shell. Es decir, si el primer argumento no contiene ninguna '/' se toma como el nombre del ejecutable y se busca en los directorios listados en la variable de entornoPATH. Si el primer argumento contiene alguna '/', se considera una ruta y se busca directamente el ejecutable en ella. -
Con 'l', como
execl()oexeclp(), los argumentos de línea de comandos para pasar al programa se indican directamente como argumentos diferentes de la función —por ejemploexecl("/bin/ls", "ls", "-l", "-a" NULL)— lo que es ideal cuando el número de argumentos es fijo. La lista de argumentos debe terminar enNULL. -
Con 'v', como
execv()oexecvp(), los argumentos de la línea de comandos para pasar al programa se indican en un array de punteros a cadenas terminadas en '\0', lo que resulta muy práctico si el número de argumentos es desconocido en el momento de compilar. El último elemento del array debe apuntar aNULL. Por ejemplo:char* argv[] = { "ls", "-l", "-a", NULL }; execv("/bin/ls", argv); -
Con 'e', como
execvpe()oexecle(), la función admite un argumento adicional para indicar el conjunto de variables de entorno con el que se ejecutará el nuevo programa. Con las otras funciones exec() se conservan las variables de entorno actuales en el proceso que llama a la función.
9.8. Procesos cooperativos
Desde el punto de vista de la cooperación podemos clasificar los procesos en dos grupos:
-
Los procesos independientes, que no afectan o pueden ser afectados por otros procesos del sistema. Cualquier proceso que no comparte datos —temporales o persistentes— con otros procesos es independiente.
-
Los procesos cooperativos, que pueden afectar o ser afectados por otros procesos ejecutados en el sistema. Los procesos que comparten datos, sea cual sea la forma en la que lo hacen, siempre son cooperativos.
9.8.1. Motivaciones para la colaboración entre procesos
Hay diversos motivos para proporcionar un entorno que permita la cooperación de los procesos:
-
Compartición de información. Dado que varios usuarios pueden estar interesados en los mismos bloques de información —por ejemplo, en un archivo compartido— el sistema operativo debe proporcionar un entorno que permita el acceso concurrente a este tipo de recursos.
-
Velocidad de cómputo. Para que una tarea se ejecute más rápido se puede partir en subtareas que se ejecuten en paralelo. Es importante destacar que la mejora en la velocidad solo es posible si el sistema tiene varios componentes de procesamiento como procesadores —si se quiere acelerar la ejecución en la CPU— o canales E/S —si se quieren acelerar las operaciones de E/S —.
-
Modularidad. Podemos querer crear nuestro software de forma modular, dividiendo las funciones del programa en procesos separados que se comunican entre sí.
-
Conveniencia. Incluso un usuario individual puede querer hacer varias tareas al mismo tiempo. Por ejemplo, editar, imprimir y compilar al mismo tiempo.
La ejecución simultánea de procesos cooperativos requiere mecanismos tanto para comunicar unos con otros como para sincronizar sus acciones (véase el Capítulo 13).
9.8.2. Comunicación entre procesos
Para comunicar procesos cooperativos existen diversas aproximaciones, que en general se pueden encajar en alguna de las siguientes estrategias:
- Memoria compartida
-
Método de comunicación en el que los procesos utilizan regiones compartidas de la memoria principal para compartir información.
- Paso de mensajes
-
Método en el que los procesos utilizan funciones del sistema operativo para enviarse mensajes entre ellos, compartiendo información y sincronizando acciones, sin necesidad de compartir memoria.
En la Figura 31 se puede un esquema comparativo entre ambos modelos de comunicación. Veremos cada uno en detalle en el Capítulo 11 y el Capítulo 10, respectivamente.
