14. Planificación de la CPU
|
Tiempo de lectura: 56 minutos |
El planificador de la CPU o planificador de corto plazo tiene la misión de seleccionar de la cola de preparados el siguiente proceso o hilo de núcleo a ejecutar. En dicha cola suelen estar los PCB —o TCB— de todos los procesos —o hilos de núcleo— que esperan una oportunidad para usar la CPU. Aunque se suele pensar en la cola de preparados como una cola FIFO, no tiene por qué ser así, como veremos más adelante, ya que existen mejores estrategias para seleccionar la próxima tarea a ejecutar.
|
En este capítulo hablaremos de procesos y de cómo son seleccionados por el planificador de la CPU. Sin embargo, debemos tener en cuenta que en los sistemas operativos multihilo con la librería de hilos implementada en el núcleo —categoría a la que pertenecen todos los sistemas modernos— la unidad de trabajo de la CPU es el hilo. Así que todo lo que comentemos a partir de ahora sobre la planificación de procesos en la CPU, realmente se aplica a los hilos y no a los procesos en los sistemas operativos modernos. |
En cualquier caso, sea cual sea el algoritmo de planificación utilizado, este debe ser muy rápido, ya que es ejecutado con mucha frecuencia —aproximadamente una vez cada 100 milisegundos—.
14.1. Planificación expropiativa
El planificador deben ser invocado necesariamente en los siguientes casos, dado que en ellos la CPU queda libre y es conveniente aprovecharla planificando otro proceso, en lugar de dejarla desocupada:
-
Cuando un proceso pasa de ejecutando a esperando. Por ejemplo, por solicitar una operación de E/S, esperar a que un hijo termine, esperar en un semáforo, etc.
-
Cuando un proceso termina.
Cuando el planificador de la CPU es invocado solo en los casos anteriores, decimos que tenemos un sistema operativo con planificación cooperativa o no expropiativa.
En la planificación cooperativa cuando la CPU es asignada a un proceso, este la acapara hasta terminar o hasta pasar al estado de esperando.
La planificación cooperativa no requiere de ningún hardware especial, por lo que en algunas plataformas puede ser la única opción. Por ello estaba presente en los sistemas operativos más antiguos, como Windows 3.x y Mac OS —que no debemos confundir con el actual macOS—.
Sin embargo, las decisiones de planificación también pueden ser tomadas en otros dos casos:
-
Cuando ocurre una interrupción del temporizador, lo que permite detectar si un proceso lleva demasiado tiempo ejecutándose.
-
Cuando un proceso pasa de esperando a preparado. Por ejemplo, porque para un proceso ha terminado la operación de E/S por la que estaba esperando.
Cuando el planificador es invocado en los cuatro casos decimos que tenemos planificación expropiativa o apropiativa.
La planificación expropiativa sí requiere de un soporte adecuado por parte del hardware, por lo que se utiliza en los sistemas operativos modernos. Ejemplos de estos sistemas son Microsoft Windows —desde Windows 95— Linux, macOS, y todos los UNIX modernos.
La utilización de un planificador expropiativo introduce algunas dificultades adicionales:
-
Puesto que un proceso puede ser expropiado en cualquier momento —sin que pueda hacer nada para evitarlo— el sistema operativo debe proporcionar mecanismos de sincronización (véase el Capítulo 13) para coordinar el acceso a datos compartidos que podrían estar siendo modificados por el proceso que abandona la CPU y que puede necesitar el que entra en ella.
-
¿Qué ocurre si un proceso va a ser expropiado en el preciso momento en el que se está ejecutando una llamada al sistema? No debemos olvidar que dentro del núcleo se manipulan datos importantes, compartidos por todo el sistema, que deben permanecer consistentes en todo momento.
Para resolver esta cuestión la solución más sencilla es impedir la expropiación dentro del núcleo. Es decir, el cambio de contexto —que sacaría al proceso actual de la CPU y metería al siguiente— no ocurre inmediatamente, sino que se retrasa hasta que la llamada al sistema se completa o se bloquea poniendo al proceso en el estado de esperando. Esto permite núcleos simples y garantiza que las estructuras del mismo permanezcan consistentes, pero es una estrategia muy pobre para sistemas de tiempo real o multiprocesador. Exploraremos otras soluciones más adelante (véase el Apartado 14.6).
14.2. El asignador
El asignador es el componente que da el control de la CPU al proceso seleccionado por el planificador de corto plazo. Esta tarea implica realizar las siguientes funciones:
-
Cambiar el contexto.
-
Cambiar al modo usuario.
-
Saltar al punto adecuado del programa para continuar la ejecución del proceso.
Puesto que el asignador es invocado para cada intercambio de procesos en la CPU, es necesario que el tiempo que tarda en detener un proceso e iniciar otro sea lo más corto posible. Al tiempo que transcurre desde que un proceso es escogido para ser planificado en la CPU hasta que es asignado a la misma se lo denomina latencia de asignación.
14.3. Criterios de planificación
Los diferentes algoritmos de planificación de la CPU tienen diversas propiedades que pueden favorecer a una clase de procesos respecto a otra. Por ello es interesante disponer de algún criterio para poder comparar los algoritmos y determinar cuál es el mejor.
Se han sugerido muchos criterios para comparar los algoritmos de planificación de CPU. La elección de uno u otro puede suponer una diferencia sustancial a la hora de juzgar qué algoritmo es el mejor.
A continuación presentamos los criterios más comunes.
14.3.1. Criterios a maximizar
Los algoritmos de planificación son mejores cuanto mayor es su valor para los siguientes criterios.
Uso de CPU
Un buen planificador debería mantener la CPU lo más ocupada posible. El uso de CPU es la proporción de tiempo que se usa la CPU en un periodo de tiempo determinado. Se suele indicar en tanto por ciento.
Tasa de procesamiento
Cuando la CPU está ocupada es porque el trabajo se está haciendo. Por tanto, una buena medida del volumen de trabajo realizado puede ser el número de tareas o procesos terminados por unidad de tiempo. A dicha magnitud es a la que denominamos como tasa de procesamiento.
14.3.2. Criterios a minimizar
Los algoritmos de planificación son mejores cuanto menor es su valor para los siguientes criterios.
- Tiempo de ejecución
-
Es el intervalo de tiempo que transcurre desde que el proceso es cargado hasta que termina.
- Tiempo de espera
-
Es la suma de tiempos que el proceso permanece a la espera en la cola de preparados. Esta medida de tiempo no incluye el tiempo de espera debido a las operaciones de E/S.
- Tiempo de respuesta
-
Es el intervalo de tiempo que transcurre desde que se lanza un evento —se pulsa una tecla, se hace clic con el ratón o llega un paquete por la interfaz de red— hasta que se produce la primera respuesta del proceso.
El tiempo de respuesta mide el tiempo que se tarda en responder y no el tiempo de E/S. Mientras que el tiempo de ejecución sí incluye el tiempo que consumen las operaciones de E/S, por lo que suele estar limitado por la velocidad de los dispositivos E/S.
14.3.3. Elección del criterio adecuado
En función del tipo de sistema o de la clase de trabajos que se van a ejecutar puede ser conveniente medir la eficiencia del sistema usando un criterio u otro. Esto a su vez beneficiará a unos algoritmos de planificación frente a otros, indicándonos cuáles son los más eficientes para nuestra clase de trabajos en particular.
En general podemos encontrar dos clases de trabajos para los que puede ser necesario evaluar la eficiencia del sistema de manera diferente: los trabajos interactivos y los que no lo son.
Sistemas interactivos
En los sistemas interactivos —ya sean sistemas de escritorio o mainframes de tiempo compartido— los procesos pasan la mayor parte del tiempo esperando algún tipo de entrada por parte de los usuarios.
En este tipo de sistemas, el tiempo de ejecución no suele ser el mejor criterio para determinar la bondad de un algoritmo de planificación, ya que viene determinado en gran medida por la velocidad de la entrada de los usuarios. Por el contrario, se espera que el sistema reaccione lo antes posible a las órdenes recibidas, lo que hace que el tiempo de respuesta sea un criterio más adecuado para evaluar al planificador de la CPU.
Generalmente, el tiempo de respuesta se reduce cuando el tiempo que pasan los procesos interactivos en la cola de preparados también lo hace —tras haber sido puestos ahí por la ocurrencia de algún evento— por lo que también puede ser una buena idea utilizar como criterio el tiempo de espera.
Esta selección de criterios no solo es adecuada para los sistemas interactivos, ya que existen muchos otros casos donde es interesante seleccionar un planificador de la CPU que minimice el tiempo de respuesta. Esto, por ejemplo, ocurre con algunos servicios en red, como: sistemas de mensajería instantánea, videoconferencia, servidores de videojuegos, etc.
Sistemas no interactivos
Por el contrario, en los antiguos mainframes de procesamiento por lotes y multiprogramados, en los superordenadores que realizan complejas simulaciones físicas y en los grandes centros de datos de proveedores de Internet como Google, lo de menos es el tiempo de respuesta y lo realmente importante es completar cada tarea en el menor tiempo posible. Por eso en ese tipo de sistemas es aconsejable utilizar criterios tales como el tiempo de ejecución o la tasa de procesamiento.
Promedio o varianza del criterio
Obviamente estos criterios varían de un proceso a otro, por lo que normalmente lo que se busca es optimizar los valores promedios en el sistema.
Sin embargo, no debemos olvidar que en muchos casos puede ser más conveniente optimizar el máximo y mínimo de dichos valores antes que el promedio. Por ejemplo, en los sistemas interactivos es más importante minimizar la varianza en el tiempo de respuesta que el tiempo de respuesta promedio, puesto que para los usuarios un sistema con un tiempo de respuesta predecible es más deseable que uno muy rápido en promedio pero con una varianza muy alta.
14.4. Ciclo de ráfagas de CPU y de E/S
El éxito de la planificación de CPU depende en gran medida de la siguiente propiedad que podemos observar en hilos o procesos:
La ejecución de un hilo o proceso consiste en ciclos de CPU y esperas de E/S, de forma que alternan entre estos dos estados.
La ejecución empieza con una ráfaga de CPU, seguida por una ráfaga de E/S, que a su vez es seguida por otra de CPU y así sucesivamente. Finalmente, la última ráfaga de CPU finaliza con una llamada al sistema —generalmente exit()— para terminar la ejecución del proceso.

La curva que relaciona la frecuencia de las ráfagas de CPU con la duración de las mismas tiende a ser exponencial o hiperexponencial (véase la Figura 43) aunque varía enormemente entre tipos de tareas y sistemas informáticos distintos. Esto significa que los procesos se pueden clasificar entre aquellos que presentan un gran número de ráfagas de CPU cortas o aquellos con un pequeño número de ráfagas de CPU largas.
Concretamente:
-
Decimos que un proceso es limitado por la E/S cuando presenta muchas ráfagas de CPU cortas, debido a que si es así, es porque pasa la mayor parte del tiempo esperando por la E/S.
-
Decimos que un proceso está limitado por la CPU cuando presenta pocas ráfagas de CPU largas, debido a que si es así, es porque hace un uso intensivo de la misma y a penas pasa tiempo esperando por la E/S.
Esta distinción entre tipos de procesos puede ser importante en la selección de un algoritmo de planificación de CPU adecuado, puesto que, por lo general el algoritmo escogido debe planificar antes a los procesos limitados por la E/S, evitando así que los procesos limitados por la CPU —que son los que tienden a usarla más tiempo— la acaparen.
Si esto último ocurriera, los procesos limitados por la E/S se acumularían en la cola de preparados, dejando vacías las colas de dispositivos. Este fenómeno, que provoca una infrautilización de los dispositivos de E/S, se denomina efecto convoy.
Planificar primero a los procesos limitados por la E/S tiene además dos efectos muy positivos:
-
Los procesos interactivos son generalmente procesos limitados por la E/S, por lo que planificarlos primero hace que mejore el tiempo de respuesta.
-
Generalmente el tiempo de espera promedio se reduce cuando se planifican primero los procesos con ráfagas de CPU cortas. Según las definiciones anteriores, estos procesos son precisamente los limitados por la E/S.
14.5. Algoritmos de planificación de la CPU
A continuación ilustraremos algunos de los algoritmos de planificación de CPU más comunes. Lo haremos considerando que cada proceso tiene una única ráfaga de CPU. Sin embargo, no debemos olvidar que para ser precisos necesitaríamos utilizar muchos más procesos, donde cada uno estuviera compuesto de una secuencia de miles de ráfagas alternativas de CPU y de E/S.
14.5.1. Planificación FCFS
En la planificación FCFS (First Come, First Served) o primero que llega, primero servido la cola es FIFO:
-
Los procesos que llegan se colocan al final de la cola que les corresponde.
-
El proceso asignado a la CPU se coge siempre del principio de la cola seleccionada.
-
Es un algoritmo cooperativo, puesto que un proceso mantiene la CPU hasta que decide liberarla voluntariamente —recordemos que la ráfaga de CPU llega a su fin porque el proceso termina o solicita alguna operación que lo lleva el estado esperando—.
Ilustremos el algoritmo con un ejemplo. Supongamos que 4 procesos llegan a la cola de preparados en los tiempos indicados en la Tabla 8. Además, aunque es difícil tener un conocimiento a priori del tiempo de la ráfaga de CPU de cada proceso, vamos a suponer que también son conocidos.
| Proceso | Tiempo de llegada (ms) | Tiempo de ráfaga de CPU (ms) |
|---|---|---|
P1 |
0 |
24 |
P2 |
1 |
3 |
P3 |
2 |
3 |
P4 |
3 |
2 |
En la siguiente figura podemos ver el diagrama de Gantt de la planificación considerando que se utiliza el algoritmo FCFS:

Utilizando el diagrama anterior, podemos calcular fácilmente los tiempos de espera y de ejecución promedio:
| Proceso | Instante de finalización (ms) | Tiempo de espera (ms) | Tiempo de ejecución (ms) | ||
|---|---|---|---|---|---|
P1 |
24 |
(0-0)= |
0 |
(24-0)= |
24 |
P2 |
27 |
(24-1)= |
23 |
(27-1)= |
26 |
P3 |
30 |
(27-2)= |
25 |
(30-2)= |
28 |
P4 |
32 |
(30-3)= |
27 |
(32-3)= |
29 |
Tiempos promedio (ms) |
18.75 |
26.75 |
|||
Lo interesante es que el resultado cambia si los procesos llegan en otro orden. Por ejemplo, P1 podría llegar el último:
| Proceso | Tiempo de llegada (ms) | Tiempo de ráfaga de CPU (ms) |
|---|---|---|
P2 |
0 |
3 |
P3 |
1 |
3 |
P4 |
2 |
2 |
P1 |
3 |
24 |
Entonces el resultado de la planificación sería el que se muestra en la siguiente figura:

Y los tiempos de espera y ejecución promedio correspondientes serían:
| Proceso | Instante de finalización (ms) | Tiempo de espera (ms) | Tiempo de ejecución (ms) | ||
|---|---|---|---|---|---|
P2 |
3 |
(0-0)= |
0 |
(3-0)= |
3 |
P3 |
6 |
(3-1)= |
2 |
(6-1)= |
5 |
P4 |
8 |
(6-2)= |
4 |
(8-2)= |
6 |
P1 |
32 |
(8-3)= |
5 |
(32-3)= |
29 |
Tiempos promedio (ms) |
2.75 |
10.75 |
|||
Aunque el tiempo total necesario para ejecutar las ráfagas de los 4 procesos, los criterios utilizados reflejan que el algoritmo se comporta mucho mejor en el segundo caso. Por tanto, el algoritmo FCFS no garantiza ni tiempos de espera ni de ejecución mínimos, ya que pueden cambiar variar considerablemente con el orden en el que llegan los procesos.
Además, el algoritmo FCFS sufre el llamado efecto convoy. Para entenderlo, analicemos lo que está pasando en el ejemplo de la Tabla 8:
-
Al proceso P1 se le asigna la CPU. Durante el tiempo que P1 utiliza la CPU todos los otros procesos terminan sus operaciones de E/S y pasan a la cola de preparados. Por tanto, mientras los procesos esperan para utilizar la CPU, los dispositivos de E/S permanecen desocupados.
-
El proceso P1 termina de usar la CPU y pasa a una cola de dispositivos.
-
El resto de procesos P, que tienen ráfagas de CPU cortas, se ejecutan rápidamente y pasan a las colas de dispositivos. Por tanto, la CPU permanecerá vacía hasta que algún proceso termine la operación de E/S solicitada.
-
El proceso P1 pasa a la cola de preparados y se le asigna la CPU. Con el tiempo el resto de procesos terminarán sus operaciones y, nuevamente, tienen que esperar en la cola de preparados a que el proceso P1 termine de utilizarla.
Esto nos permite llegar a la conclusión de que en cierto orden de llegada la mayor parte de los procesos esperan constantemente detrás de uno para poder realizar su trabajo. Esto reduce la utilización de la CPU y de los dispositivos de E/S por debajo de lo que sería posible, si los procesos más cortos se ejecutasen primero.
14.5.2. Planificación SJF
La planificación SJF (Shortest-Job First) o primero el más corto, consiste en:
-
Se asocia con cada proceso la longitud de tiempo de su siguiente ráfaga de CPU.
-
Cuando la CPU está disponible, se pone ejecutando el proceso de menor ráfaga de CPU.
-
Si dos procesos tienen ráfagas de una misma longitud, se utiliza el algoritmo FCFS —entre ellos, el que lleva más tiempo en la cola de preparados—.
-
Es un algoritmo cooperativo, puesto que un proceso mantiene la CPU hasta que decide liberarla voluntariamente.
Ilustremos el algoritmo con un ejemplo:
| Proceso | Tiempo de llegada (ms) | Tiempo de ráfaga de CPU (ms) |
|---|---|---|
P1 |
0 |
6 |
P2 |
1 |
8 |
P3 |
2 |
7 |
P4 |
3 |
3 |
Considerando que se utiliza el algoritmo SJF obtendremos el siguiente diagrama de Gantt:

Con los tiempos de espera y ejecución promedio correspondientes:
| Proceso | Instante de finalización (ms) | Tiempo de espera (ms) | Tiempo de ejecución (ms) | ||
|---|---|---|---|---|---|
P1 |
6 |
(0-0)= |
0 |
(6-0)= |
6 |
P2 |
24 |
(16-1)= |
15 |
(24-1)= |
23 |
P3 |
16 |
(9-2)= |
7 |
(16-2)= |
14 |
P4 |
9 |
(6-3)= |
3 |
(9-3)= |
6 |
Tiempos promedio (ms) |
6.25 |
12.25 |
|||
Sin embargo, si hubiéramos utilizado el algoritmo FCFS:

| Proceso | Instante de finalización (ms) | Tiempo de espera (ms) | Tiempo de ejecución (ms) | ||
|---|---|---|---|---|---|
P1 |
6 |
(0-0)= |
0 |
(6-0)= |
6 |
P2 |
14 |
(6-1)= |
5 |
(14-1)= |
13 |
P3 |
21 |
(14-2)= |
12 |
(21-2)= |
19 |
P4 |
24 |
(21-3)= |
18 |
(24-3)= |
21 |
Tiempos promedio (ms) |
8.75 |
14.75 |
|||
El algoritmo SJF es óptimo en el sentido de que el tiempo de espera promedio es mínimo, porque reduce más el tiempo de espera de los procesos cortos y aumenta el de los procesos largos. Además, así se evita el efecto convoy.
Sin embargo, la pregunta que debemos hacernos es cómo podemos conocer de antemano la longitud de las ráfagas de CPU de un proceso, para usar esa información durante la planificación. Sin analizar el código, el sistema operativo no puede conocer el tiempo de una ráfaga hasta que esta no termina de ejecutarse.
Por eso el algoritmo SJF se utiliza frecuentemente como planificador de la cola de trabajos, donde se puede obligar al usuario a especificar un tiempo de ejecución máximo, al enviar el trabajo a dicha cola. En este caso, los usuarios tenderán a ajustar la estimación de tiempo de ejecución, puesto que los que tengan tiempos más cortos serán priorizados para ser ejecutados antes, frente a los de tiempos más largos.
Para evitar que los usuarios hagan trampas indicando un tiempo de ejecución más corto que el real, con el fin de que se planifique antes su trabajo, se puede utilizar un temporizador para abortar los trabajos que excedan el tiempo de ejecución indicado por el usuario. El error puede ser notificado al usuario para que vuelva a enviar el trabajo con una estimación más realista.
Para utilizar el algoritmo SJF en el planificador de la CPU, lo único que se puede hacer es intentar predecir el tiempo de la siguiente ráfaga de CPU. Por ejemplo, se puede utilizar un promedio ponderado exponencial de los tiempos de las de ráfagas de CPU pasadas:
donde:
-
τn+1 es la estimación de tiempo de la siguiente ráfaga de CPU
-
tn es el tiempo real de la última ráfaga
-
α es el peso relativo del tiempo real de la última ráfaga.
-
τn es la estimación de tiempo de la última ráfaga.
La expresión es recursiva, dado que τn se calcula usando la ecuación con tn-1 y τn-1; que a su vez depende de tn-2 y τn-2, y así sucesivamente.
Si desarrollamos la fórmula sustituyendo los valores, veremos que tn se pondera con α, tn-1 con (1 - α)α, tn-2 con(1 - α)2α, y así sucesivamente:
Si α = 1, τn+1 = αtn, ignorando el resto del histórico. En otro caso, dado que tanto α como 1 - α son menores de 1, cada término sucesivo tiene menor peso que su predecesor, haciendo que los tn contribuyan menos cuanto más alejados del tiempo actual.
El problema es que todos estos cálculos consumen tiempo de CPU, cuando el planificador debe ser lo más rápido posible, dado que se ejecuta con mucha frecuencia.
14.5.3. Planificación SRTF
El algoritmo SJF es cooperativo, pero se puede implementar de forma expropiativa, en cuyo caso se llama SRTF (Shortest-Remaing-Time First). La diferencia está en lo que ocurre cuando un nuevo proceso llega a la cola de preparados.
En SRTF se compara el tiempo de la siguiente ráfaga de CPU del nuevo proceso, con el tiempo de ráfaga que le queda al proceso en ejecución. Si la primera magnitud es inferior, el proceso que tiene la CPU es expropiado y sustituido por el nuevo proceso. Mientras que en SJF no se hace nada. Se espera que el proceso que actualmente se está ejecutando termine su ráfaga de CPU voluntariamente.
Ilustremos el algoritmo con un ejemplo:
| Proceso | Tiempo de llegada (ms) | Tiempo de ráfaga de CPU (ms) |
|---|---|---|
P1 |
0 |
8 |
P2 |
1 |
4 |
P3 |
2 |
9 |
P4 |
3 |
5 |
El resultado es el que se muestra en el siguiente diagrama de Gantt:

Y los tiempos de espera y ejecución promedio correspondientes serían:
| Proceso | Instante de finalización (ms) | Tiempo de espera (ms) | Tiempo de ejecución (ms) | ||
|---|---|---|---|---|---|
P1 |
17 |
(0-0) + (10-1)= |
9 |
(17-0)= |
17 |
P2 |
5 |
(1-1)= |
0 |
(5-1)= |
4 |
P3 |
26 |
(17-2)= |
15 |
(26-2)= |
24 |
P4 |
10 |
(5-3)= |
2 |
(10-3)= |
7 |
Tiempos promedio (ms) |
6.50 |
13.00 |
|||
Es muy complicado predecir cuál de los dos algoritmos será mejor para un conjunto concreto de procesos. Sin embargo, debemos tener en cuenta que —aunque no lo estemos considerando en estos problemas— un algoritmo expropitativo, por lo general, provocará más cambios de contexto en los que se perderá tiempo de CPU.
Los algoritmos expropiativos también suelen ofrecer mejores tiempos de respuesta, puesto que un proceso que llega a la cola de preparados puede ser asignado a la CPU sin esperar a que el proceso que se ejecuta en ella actualmente termine su ráfaga de CPU.
14.5.4. Planificación con prioridades
En la planificación con prioridades se asocia una prioridad a cada proceso, de tal forma que el de prioridad más alta es asignado a la CPU. En caso de igual prioridad, se utiliza FCFS.
Las prioridades se suelen indicar con números enteros en un rango fijo. Por ejemplo [0-7], [0-31], [0-139] o [0-4095]. En algunos sistemas operativos los números más grandes representan mayor prioridad, mientras que en otros son los procesos con números más pequeños los que se planifican primero. En este curso utilizaremos la convención de que a menor valor, mayor prioridad.
Si las prioridades se asignan en relación al tiempo de la próxima ráfaga de CPU, su comportamiento es el mismo que el del SJF; por lo que se considera a este último un caso particular de algoritmo de planificación con prioridades.
El algoritmo de planificación con prioridades puede ser expropiativo o cooperativo:
-
En el caso expropiativo, cuando un proceso llega a la cola de preparados su prioridad es comparada con la del proceso en ejecución. Se expropia la CPU si la prioridad del nuevo proceso es superior a la prioridad del proceso que se ejecuta.
-
En el caso cooperativo, no se toma ninguna decisión cuando llega un proceso a la cola de preparados, solo cuando el que tiene asignada la CPU la abandona.
Supongamos que 5 procesos llegan a la cola de preparados en los tiempos indicados en la Tabla 9. Como en los ejemplos anteriores, aunque es difícil tener un conocimiento a priori del tiempo de las ráfagas de CPU, vamos a suponer que son conocidos. Y también que a cada proceso se le asigna, de alguna forma, una prioridad cuando llega a la cola de preparados.
| Proceso | Tiempo de llegada (ms) | Tiempo de ráfaga de CPU (ms) | Prioridad |
|---|---|---|---|
P1 |
0 |
10 |
3 |
P2 |
1 |
2 |
1 |
P3 |
2 |
3 |
4 |
P4 |
3 |
2 |
5 |
P5 |
4 |
5 |
2 |
En las condiciones anteriores, si utilizamos el algoritmo de planificación por prioridades expropiativo, obtendremos el diagrama de Gantt de la siguiente figura:

Con los tiempos de espera y ejecución promedio correspondientes:
| Proceso | Instante de finalización (ms) | Tiempo de espera (ms) | Tiempo de ejecución (ms) | ||
|---|---|---|---|---|---|
P1 |
4 |
(0-0) + (3-1) + (9-4)= |
7 |
(17-0)= |
17 |
P2 |
3 |
(1-1)= |
0 |
(3-1)= |
2 |
P3 |
20 |
(17-2)= |
15 |
(20-2)= |
18 |
P4 |
22 |
(20-3)= |
17 |
(22-3)= |
19 |
P5 |
9 |
(4-4)= |
0 |
(9-4)= |
5 |
Tiempos promedio (ms) |
7.80 |
12.20 |
|||
Mientras que si utilizamos el algoritmo de planificación por prioridades cooperativo, obtendremos el diagrama de Gantt de la siguiente figura:

Con los tiempos de espera y ejecución promedio correspondientes:
| Proceso | Instante de finalización (ms) | Tiempo de espera (ms) | Tiempo de ejecución (ms) | ||
|---|---|---|---|---|---|
P1 |
10 |
(0-0)= |
0 |
(10-0)= |
10 |
P2 |
12 |
(10-1)= |
9 |
(12-1)= |
11 |
P3 |
20 |
(17-2)= |
15 |
(20-2)= |
18 |
P4 |
22 |
(20-3)= |
17 |
(22-3)= |
19 |
P5 |
17 |
(12-4)= |
8 |
(17-4)= |
13 |
Tiempos promedio (ms) |
9.80 |
14.20 |
|||
Que estos algoritmos ofrezcan mejores o peores resultados que otros, obviamente depende de los criterios utilizados para asignar las prioridades.
Prioridades definidas internamente o externamente
Hay dos maneras de asignar las prioridades:
-
Internamente. Se utiliza una cualidad medible del proceso para calcular su prioridad. Por ejemplo, límites de tiempo, necesidades de memoria, número de archivos abiertos, tiempo estimado de ráfaga de CPU —como en SJF— o la proporción entre esta y el tiempo estimado de ráfaga de E/S.
-
Externamente. Las prioridades son fijadas por criterios externos al sistema operativo. Por ejemplo, la importancia del proceso para los usuarios, la cantidad de dinero pagada para el uso del sistema u otros factores políticos.
Algunas de estas formas de asignar las prioridades pueden ser fijas, mientras que otras pueden ser variables. Es decir, un criterio externo como es la importancia del proceso para los usuarios, puede dar lugar a una prioridad que se asigna al crear el proceso y que no cambia durante toda su ejecución. Por el contrario, un criterio como el tiempo de ráfaga de CPU puede dar lugar a una prioridad variable, que se ajusta cada vez que se tiene una estimación mejor.
Muerte por inanición
El mayor problema de este tipo de planificación es el bloqueo indefinido o muerte por inanición. Si hay un conjunto de procesos de alta prioridad demandando CPU continuamente, el algoritmo puede dejar a algunos procesos de menor prioridad esperando indefinidamente.
Una solución a este problema es aplicar mecanismos de envejecimiento. Consisten en aumentar gradualmente la prioridad de los procesos que esperan —por ejemplo, 1 unidad cada 15 minutos—. De esta manera los proceso de baja prioridad tarde o temprano tendrán una oportunidad para ejecutarse. Una vez se les asigna la CPU, se restablece su prioridad al valor original.
14.5.5. Planificación RR
El algoritmo RR (Round-Robin) es similar al FCFS, pero añadiendo la expropiación para conmutar entre procesos cuando llevan cierta cantidad de tiempo ejecutándose en la CPU.
Este algoritmo requiere los siguientes elementos:
-
Definir una ventana de tiempo o cuanto, generalmente entre 10 y 100 ms
-
Definir la cola de preparados como una cola circular, donde el planificador asigna la CPU a cada proceso en intervalos de tiempo de hasta un cuanto, como máximo.
Cuando un proceso está en la CPU pueden darse diversos casos:
-
Que la ráfaga de CPU sea menor que un cuanto. Entonces el proceso liberará la CPU voluntariamente, al terminar la ráfaga.
-
Que la ráfaga de CPU sea mayor que un cuanto. El temporizador interrumpirá el proceso al terminar el cuanto e informará al sistema operativo. Este hará el cambio de contexto para asignar la CPU al siguiente proceso y el que abandona la CPU es insertado al final de la cola de preparados.
Este algoritmo es expropiativo, puesto que los procesos son expropiados por la interrupción del temporizador. Como se puede intuir, originalmente fue diseñado para los sistemas de tiempo compartido, para repartir la CPU por igual entre los procesos de los usuarios del sistema.
Ilustremos el algoritmo con un ejemplo con cuanto de 4 ms:
| Proceso | Tiempo de llegada (ms) | Tiempo de ráfaga de CPU (ms) |
|---|---|---|
P1 |
0 |
24 |
P2 |
1 |
3 |
P3 |
2 |
3 |
El resultado es el que se muestra en el siguiente diagrama de Gantt:

Y los tiempos de espera y ejecución promedio correspondientes serían:
| Proceso | Instante de finalización (ms) | Tiempo de espera (ms) | Tiempo de ejecución (ms) | ||
|---|---|---|---|---|---|
P1 |
30 |
(0-0) + (10-4)= |
6 |
(30-0)= |
24 |
P2 |
7 |
(4-1)= |
3 |
(7-1)= |
6 |
P3 |
10 |
(7-2)= |
5 |
(10-2)= |
8 |
Tiempos promedio (ms) |
4.67 |
12.67 |
|||
Rendimiento
Cuando se utiliza la planificación RR el tamaño del cuanto es un factor clave en la eficiencia del planificador:
-
Cuando se reduce el cuanto, el tiempo de respuesta y el tiempo de espera promedio tienden a mejorar. Sin embargo el número de cambios de contexto será mayor, por lo que la ejecución de los procesos será más lenta.
Es importante tener en cuenta que interesa que el cuanto sea mucho mayor que el tiempo del cambio de contexto. Si, por ejemplo, el tiempo de cambio de contexto es un 10% del cuanto, entonces alrededor del 10% del tiempo de CPU se pierde en cambios de contexto.
-
Cuando se incrementa el cuanto, el tiempo de espera promedio también se incrementa. En el caso extremo en el que el cuanto es tan grande que ningún proceso lo agota, el RR se convierte en FCFS, que suele tener grandes tiempos de espera promedio.
Por otro lado, puede observarse experimentalmente que el tiempo de ejecución promedio generalmente mejora cuantos más procesos terminan su próxima ráfaga de CPU dentro de su cuanto. Por lo tanto, nos interesa un cuanto grande para que más procesos terminen su siguiente ráfaga dentro del mismo.
Dados tres procesos con una duración cada uno de ellos de 10 unidades de tiempo y cuanto igual a 1, el tiempo de ejecución promedio será de 29 unidades. Sin embargo, si el cuanto de tiempo fuera 10, el tiempo de ejecución promedio caería a 20 unidades de tiempo.
La regla general que siguen los diseñadores es intentar que el 80% de las ráfagas de CPU sean menores que el tiempo de cuanto. Se busca así equilibrar los criterios anteriores, evitando que el tiempo de cuanto sea demasiado grande o demasiado corto.
|
Actualmente se utilizan tiempos de cuanto de entre 10 y 100 ms Estos tiempos son mucho mayores que los tiempos de cambios de contexto, que generalmente son inferiores a 10 µs. |
Reparto equitativo del tiempo de CPU
Uno de los inconvenientes del algoritmo RR es que no garantiza el reparto equitativo del tiempo de CPU entre los procesos limitados por la E/S y los limitados por la CPU —aunque es mejor que FCFS—.
Esto es debido a que los primeros utilizan el procesador durante periodos cortos de tiempo, para bloquearse posteriormente a la espera de que se realice la operación de E/S que han solicitado. Cuando la espera termina, vuelven a la cola de preparados donde aguardan a que se les asigne la CPU. Sin embargo, eso no va a ocurrir rápidamente si en el sistema hay procesos limitados por la CPU, pues estos generalmente agotan el cuanto antes de ser forzados a volver a la cola de preparados.
Así, los procesos limitados por la CPU hacen un mayor uso de la misma, mientras que los limitados por la E/S pueden tener que esperar durante bastante tiempo —aunque menos que si el algoritmo fuera FCFS, donde no hay cuanto— en la cola de preparados antes entrar en la CPU para solicitar una nueva operación de E/S. Esto hace que se desaprovechen los dispositivos de E/S y genera un incremento de la varianza del tiempo de respuesta. Para evitarlo se puede optar por un planificador de colas multinivel —para resolver el problema combinando el algoritmo RR con otro que priorice adecuadamente los procesos limitados por la E/S (véase el Apartado 14.5.7)— o por la planificación equitativa que veremos a continuación.
14.5.6. Planificación equitativa
Hasta el momento hemos hablado de planificadores que se centran en cuál es el proceso más importante para ejecutarlo a continuación. Sin embargo otra opción, desde el punto de vista de la planificación, es dividir directamente el tiempo de CPU entre los procesos. Esto es precisamente lo que hace la planificación equitativa (Fair Scheduling) que intenta repartir por igual el tiempo de CPU entre los procesos de la cola de preparados.
Por ejemplo, si 4 procesos compiten por el uso de la CPU, el planificador asignaría un 25% del tiempo de la misma a cada uno. Si a continuación un usuario inicia un nuevo proceso, el planificador tendría que ajustar el reparto asignando un 20% del tiempo a cada uno, ya que ahora habría 5 procesos compitiendo por el tiempo de CPU.
El algoritmo de planificación equitativa es muy similar al algoritmo RR. Pero, mientras que en este último se utiliza un cuanto de tamaño fijo, en la planificación equitativa la ventana de tiempo se calcula dinámicamente para garantizar el reparto equitativo de la CPU.
Planificación equitativa ponderada
Al igual que en los algoritmos anteriores, en ocasiones puede ser interesante priorizar unos procesos frente a otros, tanto por motivos ajenos al sistema operativo como por motivos internos. Por ejemplo, se puede querer favorecer a los procesos limitados por la E/S para mejorar la eficiencia del sistema, tal y como comentamos en el apartado Apartado 14.4.
La planificación equitativa resuelve este problema permitiendo que a los procesos se les asignen pesos y repartiendo proporcionalmente más tiempo de CPU a los procesos con mayor peso. A esta generalización del planificador equitativo se la conoce como planificador equitativo ponderado.
Linux, desde la versión 2.6.23, utiliza un tipo de planificador equitativo ponderado denominado CFS (Completely Fair Scheduler) o planificador completamente equitativo (véase «Inside the Linux 2.6 Completely Fair Schedule — IBM Developer»). Otro ejemplo es Zircon —el microkernel de Google Fuchsia— que está inmerso en cambiar su actual planificador basado en colas multinivel con prioridades a una implementación del planificador equitativo ponderado (véase «Zircon Fair Scheduler — Fuchsia Project»).
Implementación
Para ilustrar como funciona este tipo de planificadores, vamos a describir brevemente una posible implementación basada en la de Zircon.
Zircon es un microkernel multihilo con modelo uno a uno, por lo que su planificador trabaja con hilos. Es decir, las propiedades que necesita el planificador para hacer su trabajo están vinculadas a los hilos y son estos hilos los que el planificador ordena y selecciona para ser ejecutados en la CPU. Por el contrario, en la versión que vamos a describir los hilos no existen. En su lugar hablaremos de planificar procesos en la CPU, por coherencia con cómo hemos explicado el resto de planificadores de este capítulo.
Este planificador tiene una serie de parámetros ajustables:
-
La granularidad mínima M, es la porción mínima de tiempo de CPU que se puede asignar a cualquier proceso.
-
La latencia de planificación L, es el periodo de tiempo en el que todos los procesos deben haber sido planificados aproximadamente una vez en la CPU.
Lo que hace el planificador es repartir periodos de tiempo L entre todos los procesos que compiten por la CPU, para que todos tengan una oportunidad de ejecutarse en intervalos de al menos L segundos.
Como en otros planificadores, los procesos listos para ejecutarse en un instante dado se almacenan en la cola de preparados. Cada proceso Pi tiene una serie de propiedades:
-
Peso wi, que indica el peso relativo del proceso en el reparto del tiempo de CPU. Se trata de un número real en el intervalo (0.0, 1.0].
-
Instante inicial Tsi de la ráfaga de CPU del proceso, en el tiempo virtual de la CPU.
-
Instante final Tfi de la ráfaga de CPU del proceso, en el tiempo virtual de la CPU.
-
Cuanto del tiempo de CPU Ti en el periodo actual. Como ocurre con el cuanto en la planificación RR, se trata del tiempo máximo que el proceso puede estar de forma continua en la CPU.
El concepto de tiempo virtual es muy común en este tipo de planificadores. Es como si cada proceso tuviera su propia dimensión temporal, de forma que el tiempo fluyera más despacio para los procesos con mayor peso wi. Así, una unidad de tiempo virtual para un proceso muy pesado implica más tiempo real, que la misma unidad para un proceso muy ligero.
Sea t es el instante de tiempo en el que un proceso Pi entra en la cola de preparados, en relación al tiempo virtual el proceso comienza a ejecutarse en la CPU desde ese mismo instante y necesitará más tiempo para terminar cuanto mayor sea su peso. Por lo tanto, podemos calcular el instante inicial Tsi y el instante final Tfi de la siguiente manera:
El tiempo virtual no es el tiempo real en la CPU. Por lo tanto, el proceso Pi no entrará en la CPU nada más llegar en t, pero si se colocará en la cola de preparados en orden ascendente en relación al instante final Tfi. Es decir, los procesos con mayor peso wi se colocarán antes en la cola de preparados, con bastante probabilidad.
Cuando un proceso Pi es seleccionado para pasar al estado ejecutando, se calcula su cuanto de tiempo. Como el tiempo se asigna en múltiplos de M, primero es necesario saber cuantas unidades de tiempo M tiene el periodo de latencia de planificación L, que es el tiempo máximo que se le podría asignar si el proceso estuviera solo:
A cada proceso le corresponde más tiempo de CPU según su peso en relación al resto de procesos en competición, lo que lleva a calcular el peso relativo ri como:
donde W es la suma de los pesos de todos los procesos en competición por la CPU —en la cola de preparados— más el peso del que se está ejecutando.
Cuando un proceso entra en la cola de preparados su peso se suma a W, mientras que cuando pasa al estado esperando o termina, su peso se resta.
Finalmente, podemos calcular el cuanto del proceso Pi:
Esta definición asegura que Ti sea un entero múltiplo de la granularidad mínima M, mientras es aproximadamente proporcional al peso del proceso respecto al resto de procesos con los que compite.
Ilustremos el algoritmo con un ejemplo con L = 5 y M = 1:
| Proceso | Tiempo de llegada (ms) | Tiempo de ráfaga de CPU (ms) | Peso |
|---|---|---|---|
P1 |
0 |
10 |
0.3 |
P2 |
1 |
2 |
0.1 |
P3 |
2 |
3 |
0.4 |
P4 |
3 |
2 |
0.5 |
P5 |
4 |
5 |
0.2 |
El resultado es el que se muestra en el siguiente diagrama de Gantt:

Como el primer proceso está solo cuando se le asigna la CPU, puede consumir toda la latencia de planificación L en el primer periodo. Sin embargo, ya han llegado el resto de procesos del problema cuando es expulsado de la CPU, por lo que a partir de ese momento tiene que competir con ellos. Entonces, el orden para asignar la CPU viene determinado por el peso y el tiempo de cuanto por la expresión para Ti que vimos anteriormente.
Una vez resuelto el problema, los tiempos de espera y ejecución promedio correspondientes serían:
| Proceso | Instante de finalización (ms) | Tiempo de espera (ms) | Tiempo de ejecución (ms) | ||
|---|---|---|---|---|---|
P1 |
17 |
(0-0) + (9-5) + (14-11)= |
7 |
(17-0)= |
17 |
P2 |
22 |
(12-1) + (21-13)= |
19 |
(22-1)= |
21 |
P3 |
14 |
(13-2)= |
11 |
(14-2)= |
12 |
P4 |
7 |
(5-4)= |
1 |
(7-3)= |
4 |
P5 |
21 |
(11-5) + (17-12)= |
11 |
(21-4)= |
17 |
Tiempos promedio (ms) |
9.80 |
14.20 |
|||
14.5.7. Planificación con colas multinivel
Los diseñadores recurren a la planificación de colas multinivel cuando quieren combinar las características de varios algoritmos.
En la planificación con colas multinivel se divide la cola de preparados en colas separadas. Los procesos son asignados permanentemente a alguna de dichas colas, cada una de las cuales puede tener un algoritmo de planificación distinto.
La asignación de un proceso a una cola se hace en relación a alguna una característica del proceso. Por ejemplo, si es interactivo o no, su prioridad o su tamaño en memoria. Se hace de esta manera porque se supone que los procesos se pueden clasificar, y que cada clase tiene diferentes requerimientos. Por ejemplo, si los procesos se clasifican en interactivos o no interactivos, los primeros pueden ir a una cola con planificación RR mientras los segundos van a una con FCFS.

Una cuestión interesante es cómo seleccionar la cola que debe escoger al siguiente proceso a ejecutar:
-
Una opción común en los sistemas actuales es utilizar un planificador con prioridades. Es decir, que cada cola tenga una prioridad y así el planificador solo tiene que escoger la cola de prioridad más alta que no esté vacía.
Por ejemplo, en la Figura 44, mientras un proceso de prioridad 1 esté preparado, no se escoge ningún otro de prioridad inferior. Si este planificador se implementa de forma expropiativa, el proceso que tiene asignada la CPU es expulsado si un proceso entra en una de las colas que tiene mayor prioridad que la suya.
-
Otra opción es usar cuantos sobre las colas. Es decir, que a cada cola se le asigne una porción del tiempo de la CPU que debe repartirse entre los distintos procesos en la misma.
Por ejemplo, un 80% de CPU para la cola de procesos interactivos, con planificación RR, y el 20% de CPU restante para la cola de procesos no interactivos, con planificador FCFS.
La planificación de colas multinivel con un planificador con prioridades para escoger la cola adecuada, es con diferencia la opción más común en los sistemas operativos modernos. Sin embargo, en este tipo de colas multinivel la asignación de los procesos a las colas es permanente —si la asignación se hace por prioridad, significa que la prioridad es fija—. Mientras que hoy en día es común que los procesos se muevan entre colas según las características del proceso.
14.5.8. Planificación con colas multinivel realimentadas
Para aumentar la flexibilidad de la planificación con colas multinivel se puede permitir a los procesos pasar de una cola a otra. Así se pueden clasificar en colas distintas, procesos con diferentes tiempos de ráfaga de CPU. Por ejemplo, para situar los procesos interactivos o limitados por la E/S en las colas de más alta prioridad, lo que ya hemos discutido que mejora los tiempos de espera y de respuesta y evita el efecto convoy.

Por ejemplo, supongamos un planificador de colas multinivel donde cada cola tiene una prioridad, así que se usa la planificación con prioridades para seleccionar la cola. En las colas se usa el algoritmo RR para seleccionar el siguiente proceso, siendo el cuanto de la cola mayor cuanto menos prioritaria es la cola (véase la Figura 45). Los procesos que llegan nuevos o desde el estado esperando lo hacen con la prioridad más alta —que por convención hemos decidido que sea 0— así que se insertan en la cola correspondiente. Mientras que los procesos expropiados por vencimiento del cuanto pierde un punto de prioridad, siendo insertados en una cola de prioridad menor.
Con este algoritmo los procesos limitados por E/S suelen ejecutarse la mayor parte del tiempo con prioridades más altas que los limitados por CPU. Por ejemplo, usando los valores del esquema de la Figura 45, los procesos de ráfagas de CPU entre 20 y 80 ms acaban cayendo a la cola de prioridad 1 tras 20 ms de ejecución. Así dejan paso a los procesos con ráfagas menores de 20 ms, que siempre se ejecutan con prioridad 0. Finalmente, los procesos de ráfagas mayores de 80 ms van a la cola FCFS, desde donde solo tendrán acceso a la CPU cuando no haya ningún proceso de los otros tipos en la cola de preparados
El planificador de colas multinivel realimentadas también se puede utilizar para pasar a colas superiores los procesos que han esperado mucho tiempo en colas inferiores, evitando la muerte por inanición, que puede afectar a los sistemas de planificación de colas multinivel con prioridad fija.
Por ejemplo, el algoritmo RR virtual es un caso de planificador de colas multinivel realimentadas que resuelve los problemas del RR, en cuanto al reparto de la CPU entre procesos limitados por la E/S y limitados por la CPU (véase el Apartado 14.5.5.2).

Tal y como se ilustra en la Figura 46, en el RR virtual los procesos por lo general tienen prioridad 1. Sin embargo, aquellos que vuelven al estado preparado desde esperando después de una operación de E/S, obtienen una bonificación en la propiedad que los lleva a tener prioridad 0. Por tanto, los procesos que usan con más frecuencia la E/S, usan más la cola de prioridad más alta, por lo que se les asigna antes la CPU mayor frecuencia.
Esta solución puede llevar a que si hay muchos procesos limitados por la E/S, estos acaparen la CPU y no den oportunidad de ejecutarse a los procesos en la cola de prioridad 1. Para evitarlo, el algoritmo RR de la cola de prioridad 0 tiene un cuanto variable, de tal forma que cada proceso recibe lo que le queda del cuanto de la cola de prioridad 1 tras haber consumido parte en la CPU en la ráfaga anterior. Esto hace que incluso los procesos con ráfagas de CPU más cortas acaben consumiendo su cuanto en la cola de prioridad 0 y terminen cayendo a la cola de prioridad 1, dando oportunidad de ejecutarse a otros procesos.
Para ilustrar los visto hasta el momento sobre la planificación de la CPU en sistemas operativos modernos, vamos a comentar las principales características de las últimas versiones de Microsoft Windows a este respecto.
Las actuales versiones de sistemas operativos Windows pertenecen a la familia de Microsoft Windows NT; que nació con el sistema operativo Windows NT 3.1 en 1993 y que llega hasta hoy en día con Microsoft Windows 10 y Windows Server 2019 —que se corresponden con la versión 10.0 de dicha familia Windows NT—
El núcleo de la familia Windows NT es multihilo e internamente implementa un algoritmo de planificación expropiativa con colas multinivel realimentadas basado en prioridades.
En Windows las prioridades de los hilos se pueden ver desde dos perspectivas: la de Windows API y la del núcleo. Ambas tienen una organización muy diferente, pero en última instancia, las primeras deben traducirse en las segundas.
| Clase | Valor |
|---|---|
REALTIME_PRIORITY_CLASS |
0x00000100 |
HIGH_PRIORITY_CLASS |
0x00000080 |
ABOVE_NORMAL_PRIORITY_CLASS |
0x00008000 |
NORMAL_PRIORITY_CLASS |
0x00000020 |
BELOW_NORMAL_PRIORITY_CLASS |
0x00004000 |
IDLE_PRIORITY_CLASS |
0x00000040 |
Desde el punto de vista de Windows API, todo proceso pertenece a alguna de las 6 clases de prioridad de la Tabla 10.
La clase de prioridad de un proceso se puede indicar durante la creación del proceso, a través del argumento dwCreationFlags de la función CreateProcess(), o sea puede obtener y cambiar con las funciones GetPriorityClass() y SetPriorityClass(), respectivamente.
Por lo general, la clase de prioridad NORMAL_PRIORITY_CLASS es la clase por defecto de cualquier proceso nuevo, excepto que se indique otra cosa durante su creación.
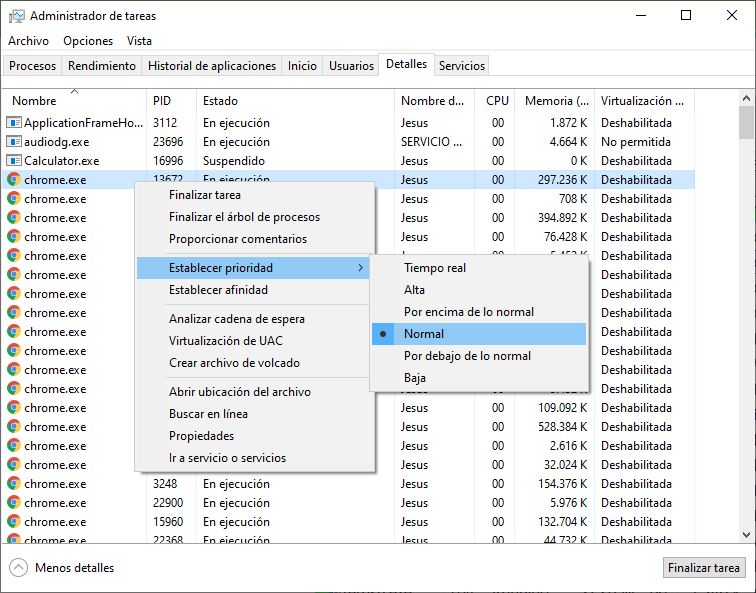
Con el Administrador de tareas de Windows podemos alterar fácilmente la clase de prioridad de un proceso durante su ejecución (véase la Figura 47).
| Prioridad | Valor |
|---|---|
THREAD_PRIORITY_TIME_CRITICAL |
15 |
THREAD_PRIORITY_HIGHEST |
2 |
THREAD_PRIORITY_ABOVE_NORMAL |
1 |
THREAD_PRIORITY_NORMAL |
0 |
THREAD_PRIORITY_BELOW_NORMAL |
-1 |
THREAD_PRIORITY_LOWEST |
-2 |
THREAD_PRIORITY_IDLE |
15 |
Al mismo tiempo, cada hilo del sistema tiene alguno de las prioridades de la Tabla 11.
La prioridad de un hilo recién creado es THREAD_PRIORITY_NORMAL, pero se puede cambiar usando la función SetThreadPriority().
El núcleo de Windows tiene 32 prioridades, siendo 31 la prioridad más alta y 0 la más baja.
Estos valores se dividen en dos rangos.
El rango de prioridades de tiempo real va de 16 a 31 y solo está disponible para hilos en procesos en la clase de prioridad REALTIME_PRIORITY_CLASS.
Mientras que el rango de prioridades dinámicas va de 1 a 15.
El nivel 0 está reservado para el sistema y se usa para una rutina especializada en limpiar zonas de memoria liberada por los procesos, poniéndolas a 0.
La prioridad base —o prioridad estática— de cada hilo que ve el núcleo se calcula combinando la prioridad del hilo y la clase de prioridad del proceso al que pertenece.
Clase de prioridad del proceso |
||||||
|---|---|---|---|---|---|---|
REALTIME |
HIGH |
ABOVE NORMAL |
NORMAL |
BELOW NORMAL |
IDLE |
|
TIME CRITICAL |
31 |
15 |
15 |
15 |
15 |
15 |
HIGHEST |
26 |
15 |
12 |
10 |
8 |
6 |
ABOVE NORMAL |
25 |
15 |
11 |
9 |
7 |
6 |
NORMAL |
24 |
13 |
10 |
8 |
6 |
4 |
BELOW NORMAL |
23 |
12 |
9 |
7 |
5 |
3 |
LOWEST |
22 |
11 |
8 |
6 |
4 |
2 |
IDLE |
16 |
1 |
1 |
1 |
1 |
1 |
Esta prioridad base es la prioridad real del hilo, si este tiene una prioridad en el rango de tiempo real —es decir, si el proceso al que pertenece está en la clase de prioridad REALTIME_PRIORITY_CLASS—.
Mientras que para el resto de hilos, el sistema suma ciertas bonificaciones a la prioridad base para calcular la prioridad dinámica, que es con la que realmente será planificado el hilo.
Estas bonificaciones se truncan para que nunca puedan hacer que el hilo se meta en el rango de tiempo real.
La prioridad real la usa el sistema para determinar a qué cola va el hilo cuando va a ser insertado en la cola de preparados. Para cada nivel de prioridad hay una cola con algoritmo RR, de tal forma que el planificador escoge primero a los hilos con prioridad más alta. Dentro de la misma prioridad la CPU se asigna en turno, dándoles un cuanto de tiempo de CPU.
Cuando llega un hilo a la cola de preparados, expropia la CPU al hilo que la tiene asignada si este tiene menor prioridad. Esto puede ocurrir incluso si el hilo a expropiar está en medio de una llamada al sistema, ya que, como cualquier sistema operativo moderno, el núcleo de Windows es expropiable —lo que veremos en el Apartado 14.6.4.2 que ofrece latencias de asignación más bajas que si no lo fuera—.
Respecto al cuanto, desde Windows Vista –NT 6.0– no se usa el temporizador para controlarlo sino el contador de ciclos de reloj de la CPU. Así el sistema puede determinar con precisión el tiempo que se ha estado ejecutando un hilo, excluyendo los tiempos dedicados a otras cuestiones, como por ejemplo a manejar interrupciones.
|
Desde el Intel Pentium las CPU de la familia x86 incorporan un contador de marca de tiempo (Time Stamp Counter o TSC) de 64 bits que indica el número de ciclos transcurridos desde el último reinicio del procesador. Para más información véase «Time Stamp Counter — Wikipedia». |
Una característica curiosa es que los hilos expropiados se insertan en la cabeza de su cola —no en el final— y conservan lo que les queda de cuanto. Mientras que se insertan por el final con el valor de cuanto reiniciado cuando abandonan la CPU por haber agotado el cuanto anterior. Estos últimos, además, pierden un nivel de prioridad si se ejecutaban con una prioridad superior a su prioridad base, a causa de alguna modificación.
Las bonificaciones a los hilos en el rango de prioridades dinámicas vienen determinadas por distintos criterios, escogidos para mejorar el tiempo respuesta y el tiempo de espera —priorizando los procesos limitados por E/S— evitar la muerte por inanición y la inversión de prioridad.
Se bonifican los hilos que despiertan tras completar operaciones de E/S con una cantidad que depende del tipo de dispositivo. Por ejemplo, la bonificación es mejor para hilos que han esperado por el teclado o el ratón que para los que esperaron por dispositivos del almacenamiento. También son bonificados los hilos que despiertan de eventos, semáforos y de otros objetos de sincronización. En este último caso, incluso se les ofrece más tiempo de cuanto si es el hilo asociado a la ventana de primer plano, con el objetivo de mejorar la respuesta de las aplicaciones interactivas. También se bonifica cualquier hilo que gestione elementos de la interfaz gráfica cuando despierta para responder a eventos del sistema de ventanas.
Para evitar la muerte por inanición, el planificador escoge cada segundo unos pocos hilos que llevan esperando aproximadamente 4 segundos, les triplica el cuanto y les aumenta la prioridad a 15. Estos hilos recuperan su prioridad base y el cuanto anterior cuando agotan el tiempo de cuanto actual o son expropiados de la CPU
14.6. Planificación de tiempo real
En el Apartado 2.7 discutimos la importancia de los sistemas de tiempo real. A continuación, describiremos las funcionalidades necesarias para soportar la ejecución de procesos en tiempo real dentro de un sistema operativo de propósito general.
14.6.1. Tiempo real estricto
Los sistemas de tiempo real estricto son necesarios para realizar tareas críticas que deben ser completadas dentro de unos márgenes de tiempo preestablecidos.
Generalmente las tareas son entregadas al sistema operativo junto con una declaración de las restricciones de tiempo —periodicidad y límite de tiempo— y la cantidad de tiempo que necesitan para ejecutarse. El planificador solo admitirá las tareas si puede garantizar el cumplimiento de las restricciones de tiempo, rechazándolas en caso contrario.
El ofrecer estas garantías requiere que el planificador conozca exactamente el tiempo máximo que se tarda en realizar todas y cada una de las funciones del sistema operativo. Esto es imposible en sistemas con almacenamiento secundario o memoria virtual, ya que introducen variaciones no controladas en la cantidad de tiempo necesario para ejecutar una tarea. Por tanto, el tiempo real estricto no es compatible con los sistemas operativos de propósito general, como los sistemas operativos de escritorio modernos.
14.6.2. Tiempo real flexible
La ejecución de procesos de tiempo real flexible es menos restrictiva. Tan solo requiere que los procesos críticos reciban mayor prioridad que los que no lo son. Esto puede generar excesos en la cantidad de recursos asignados a los procesos de tiempo real, así como inanición y grandes retrasos en la ejecución del resto de los procesos, pero es compatible con los sistemas de propósito general.
Además nos permite conseguir sistemas de propósito general que soporten multimedia, videojuegos y otras tareas que no funcionan de manera aceptable en un entorno que no implementara tiempo real flexible. Por ello, la mayor parte de los sistemas operativos modernos soportan este tipo de tiempo real.
14.6.3. Implementación del soporte de tiempo real
Implementar el soporte de tiempo real flexible en un sistema operativo de propósito general requiere:
-
Sistema operativo con planificación con prioridades. Los procesos de tiempo real deben tener la mayor prioridad y ser fija. Es decir, no deben ser afectados por ningún mecanismo de envejecimiento o bonificación, que pueda usarse con los procesos de tiempo no real.
-
Baja latencia de asignación. Cuanto menor es la latencia, más rápido comenzará a ejecutarse el proceso de tiempo real después de ser seleccionado por el planificador de la CPU.
Mientras que el primer requerimiento es bastante sencillo de conseguir, el segundo es mucho más complejo.
14.6.4. Reducir la latencia de asignación
Muchos sistemas operativos tienen un núcleo no expropiable. Estos núcleos no pueden realizar un cambio de contexto mientras se está ejecutando código del núcleo —por ejemplo, debido a una llamada al sistema— por lo que se ven obligados a esperar hasta que la operación que se esté realizando termine, antes de asignar la CPU a otro proceso. Esto aumenta la latencia de asignación, dado que algunas llamadas al sistema pueden ser muy complejas y requerir mucho tiempo para completarse.
Con el objetivo de resolver este problema se han desarrollado diversas alternativas para que el código del núcleo sea expropiable.
Puntos de expropiación
Una posibilidad es introduciendo puntos de expropiación en diversos lugares «seguros» dentro del código. En dichos puntos se comprueba si algún proceso de prioridad más alta está en la cola de preparados. En caso de que sea así, se expropia la CPU al proceso actual y se le asigna al proceso de más alta prioridad.
Debido a la función que realizan los puntos de expropiación, solo pueden ser colocados en lugares seguros del código del núcleo. Es decir, lugares donde no se interrumpe la modificación de estructuras de datos. Sin embargo, esto limita el número de puntos que pueden ser colocados, por lo que la latencia de asignación puede seguir siendo muy alta para algunas operaciones muy complejas del núcleo.
Núcleo expropiable
Otra posibilidad es diseñar un núcleo completamente expropiable.
Puesto que en este caso la ejecución de cualquier operación en el núcleo puede ser interrumpida en cualquier momento por procesos de mayor prioridad que el que actualmente tiene asignada la CPU, es necesario proteger las estructuras de datos del núcleo con mecanismos de sincronización. Esto hace que el diseño de un núcleo de estas características sea mucho más complejo.
Microsoft Windows —desde Windows NT— Linux —desde la versión 2.6— Solaris y NetBSD son algunos ejemplos de sistemas operativos con núcleos expropiables. En el caso concreto de Solaris la latencia de asignación es inferior a 1 ms, mientras que con la expropiación del núcleo desactivada esta puede superar los 100 ms
Inversión de prioridad
Supongamos que en un núcleo completamente expropiable, un proceso de baja prioridad es interrumpido porque hay un proceso de alta prioridad en la cola de preparados. Y que esto ocurre mientras el primero accede a una importante estructura de datos del núcleo.
Durante su ejecución, el proceso de alta prioridad podría intentar acceder a la misma estructura que trataba de manipular el proceso de baja prioridad cuando fue interrumpido. Debido al uso de mecanismos de sincronización, el proceso de alta prioridad se quedaría bloqueado y tendría que abandonar la CPU a la espera de que el de baja, libere el acceso al recurso. Sin embargo, este último tardará en ser asignado a la CPU mientras haya algún otro proceso de alta prioridad en la cola de preparados.
Al hecho de que un proceso de alta prioridad tenga que esperar por uno de baja se le conoce como inversión de la prioridad. Para resolverlo se utiliza un protocolo de herencia de la prioridad, donde un proceso de baja prioridad hereda la prioridad del proceso de más alta prioridad que espera por un recurso al que el primero está accediendo. En el momento en que el proceso de baja prioridad libere el acceso a dicho recurso, su prioridad retornará a su valor original.
14.7. Planificación en sistemas multiprocesador
Para tratar el problema de la planificación en los sistemas multiprocesador nos limitaremos al caso de los sistemas homogéneos. En dichos sistemas los procesadores son idénticos, por lo que, en cualquiera de ellos, puede ejecutar cualquier proceso. Esto es bastante común y simplifica el problema de la planificación.
|
Un ejemplo de lo contrario a un sistema homogéneo —un sistema heterogéneo— se puede observar en los PC modernos, donde muchos disponen tanto de una CPU como de una GPU, especializada en el procesamiento de gráficos y en las operaciones vectoriales con números enteros y de coma flotante. |
Aun así, no debemos olvidar que incluso en el caso de los sistemas homogéneos pueden aparecer limitaciones en la planificación. Por ejemplo, los procesadores SMT (Simultaneous Multithreading) permiten la ejecución concurrente de varios hilos de ejecución como si de varias CPU se tratara. Sin embargo, al no disponer cada hilo de una CPU completa, es posible que algunos debán esperar a que algún otro libere unidades de ejecución de la CPU que le son necesarias. Eso debe ser tenido en cuenta por el planificador con el fin de optimizar el rendimiento del sistema.
|
La tecnología Hyper-threading disponible en algunos procesadores de Intel es una implementación de la tecnología Simultaneous Multithreading. Permite que cada núcleo de procesador que está presente físicamente, el sistema operativo lo gestione como dos núcleos virtuales —o lógicos— y repartir entre ellos las tareas cuando es posible. |
Al margen de estas cuestiones, según el tipo de procesamiento, existen diversas posibilidades a la hora de enfrentar el problema de la planificación en un sistema multiprocesador (véase el Apartado 2.4).
14.7.1. Multiprocesamiento asimétrico
Cuando utilizamos multiprocesamiento asimétrico todas las decisiones de planificación, procesamiento de E/S y otras actividades son gestionadas por el núcleo del sistema ejecutándose en un único procesador: el servidor o maestro. El resto de procesadores se limitan a ejecutar código de usuario, que les es asignado por ese procesador maestro.
Este esquema es sencillo, puesto que evita la necesidad de compartir estructuras de datos entre el código que se ejecuta en los diferentes procesadores.
14.7.2. Multiprocesamiento simétrico
Cuando utilizamos multiprocesamiento simétrico o SMP, cada procesador ejecuta su propia copia del núcleo del sistema operativo y se autoplanifica mediante su propio planificador de CPU. En estos sistemas nos podemos encontrar con varias alternativas.
Con una cola de preparados común
Algunos sistemas disponen de una cola de preparados común para todos los procesadores. Puesto que se mira en una única cola, todos los procesos pueden ser planificados en cualquier procesador.
Este esquema requiere el uso mecanismos de sincronización para controlar el acceso concurrente de los núcleos a las colas. En caso contrario, varios procesadores podrían escoger y ejecutar el mismo proceso a la vez.
Muchos sistemas operativos modernos implementan el esquema SMP con una cola de preparados común. Esto incluye Microsoft Windows NT/2000/XP, Solaris, macOS y versiones anteriores a Linux 2.6.
|
Es importante recordar que en esos sistemas operativos, lo que se planifica en las distintas CPU usando alguna de estas estrategias, son los hilos y no los procesos. |
Sin embargo, esta solución presenta algunos inconvenientes:
-
La posibilidad de que un proceso se pueda ejecutar en cualquier CPU —aunque parezca beneficiosa— es negativa desde el punto de vista de que dejan de ser útiles las cachés de los procesadores, penalizando notablemente el rendimiento del sistema. Por eso, la mayoría de los sistemas operativos de este tipo evitan, en lo posible, la migración de procesos de un procesador a otro. A esto se lo conoce como asignar al proceso afinidad al procesador.
-
Los mecanismos de sincronización requeridos para controlar el acceso a la cola de preparados pueden mantener a los procesadores mucho tiempo desocupados —mientras esperan— en sistemas con un gran número de procesadores y con muchos procesos en la cola de preparados.
Con una cola para cada procesador
Cada vez más sistemas modernos están optando por utilizar el esquema SMP con una cola de preparados por procesador. De esta manera, al no utilizar mecanismos de sincronización, se eliminan los tiempos de espera para acceder a la cola de preparados y escoger un nuevo proceso.
El mayor inconveniente de esta solución es que puede generar desequilibrios entre los procesadores, ya que un procesador puede acabar desocupado —con su cola de preparados vacía— mientras otro está muy ocupado. Con el fin de que esto no suceda, es necesario que el sistema disponga de algunos mecanismos de balanceo de carga:
-
En la migración comandada o push migration, una tarea específica —que se ejecuta con menor frecuencia que el planificador de la CPU— estima la carga de trabajo de cada CPU y en caso de encontrar algún desequilibrio mueve algunos procesos de la cola de preparados de unos procesadores a la de los otros.
-
En la migración solicitada o pull migration, un procesador inactivo extrae de la cola de preparados de un procesador ocupado alguna tarea que esté esperando.
Tanto el planificador de Linux 2.6 y posteriores, como el planificador ULE de FreeBSD, implementan ambas técnicas. Mientras que en Microsoft Windows, a partir de Windows Vista también se utiliza una cola de preparados por procesador, pero solo implementa la migración solicitada.